
티스토리 뷰
Meta에서 23년 7월 19일에 공개한 이후, 수많은 LLM들의 foundation model로 사용되고 있는 LLaMA 2에 대해 정리하려고 한다.
LLaMA 2 논문 과 daewoo kim님의 블로그 를 참조하여 작성하였음을 밝힌다. 해당 블로그에 정리가 잘 되어 있어 도움을 많이 받았다.
(노션에 가볍게 정리하다가 꽤 길어져서 블로그에 옮기는 중. 티스토리에서 그림이 자꾸 깨진다ㅠ)
- LLaMA 2 (23년 7월 공개)는 LLaMA 1 (23년 2월 공개)를 발전시킨 모델
- self-supervised learning으로 학습
- 사전학습 데이터 40% 증가 (1.4T tokens → 2T tokens)
- Context length 2배 증가 (2K → 4K)
- Grouped-query attention 사용
- Foundation 버전과 fine-tuned Chat 버전 공개
- 모델 크기: 7B, 13B, 70B (34B도 개발되었지만 아직 공개되지않음)
- 성능 평가
- open-source 모델과의 비교 => LLaMA 2가 가장 우수한 성능을 보였음
- closed-source 모델과의 비교 => PaLM보다는 더 낫고 GPT-3.5와는 근접한 성능. but, GPT-4와 PaLM-2-L에는 크게 뒤쳐지는 성능

- Llama 2와 Llama-2-chat의 학습 과정
- Chat 버전
- Step 1: LLaMA 2를 supervised fine-tuning (SFT)
- 처음에는 공개된 instruct 데이터로 SFT를 하였으나, 데이터의 다양성과 품질이 낮아 alignment가 어려움을 확인함
→ 적지만 고품질의 데이터(27k)를 수집함
→ 그 결과 성능이 향상되는 것을 확인 - 학습 데이터는 Prompt - Response 로 구성됨
- Prompt의 토큰들에 대한 loss를 0으로 만들고, Response의 토큰들에 대해서만 back-propagation을 진행
- 처음에는 공개된 instruct 데이터로 SFT를 하였으나, 데이터의 다양성과 품질이 낮아 alignment가 어려움을 확인함
- Step 1: LLaMA 2를 supervised fine-tuning (SFT)
- Step 2: RLHF 적용
- Human preference 데이터 수집
- Reward Modeling을 위해 데이터를 수집하는 과정
- Annotator가 prompt를 작성 → 샘플링된 2개의 모델 응답 중에 선호하는 응답을 선택 → 선택한 응답에 대한 Preference annotation 수행 → Safety annotation 수행
- Preference annotation 선택지
- 1) significantly better
- 2) better
- 3) slightly better
- 4) negligibly better/unsure
- Preference annotation은 helpfulness와 safety 측면에 집중함
- Safety annotation 선택지
- 1) 선호하는 응답은 안전하지만 다른 응답은 안전하지 않음
- 2) 두 응답 모두 안전
- 3) 두 응답 모두 안전하지 않음
- Preference annotation 선택지
- 기존 공개된 human preference 데이터와 비교했을 때, 새로 수집한 데이터는 평균적으로 더 길고 더 많은 turn 수를 가짐
- Reward Modeling
- 수집한 human preference 데이터 (prompt - response)를 바탕으로, 생성된 응답의 점수를 (helpfulness & safetyness 측면에서) 매기는 reward model (RM)을 만듦
- 이 RM을 통해, LLaMA2-chat 모델을 인간의 선호도에 최적화하였음
- helpfulness와 safetyness가 trade-off 관계임을 발견 ⇒ 단일 RM을 helpfulness RM과 safety RM로 분리하여 학습 및 최적화
- 각 RM은 fine-tuned LLaMA2-chat 모델의 checkpoint로 initialization되었음
⇒ RM이 LLaMA2-chat 모델이 아는 것을 알기 때문에, 정보 불일치로 인한 hallucination을 방지하는 효과가 있음
- 각 RM은 fine-tuned LLaMA2-chat 모델의 checkpoint로 initialization되었음
- 성능 비교 결과
- StreamSHP-XL (FLAN-T5-xl 기반), Open Assistant (DeBERTa-V3-large 기반 RM), GPT-4 (OpenAI’s API)와 비교하였을 때, LLaMA 2의 RM들이 가장 우수한 성능을 냄
- 다만 GPT-4는 Reward Modeling task를 목표로 학습되지 않았음에도 우수한 성능을 보이더라
- 정리: 두 개의 분리된 RM을 최적화하는 것이 Reward Modeling task를 단순화시키며, helpfulness와 safetyness 두 가지 목표 간의 잠재적인 긴장(tension)을 통해 성능 향상을 이룸
- Iterative Fine-tuning
- human preference 데이터가 늘어남에 따라, RLHF 모델을 연속적인 버전으로 학습시킴 (RLHF-V1, …, RLHF-V5)
- RLHF Iterative Fine-tuning에는 다음의 두가지 메인 알고리즘이 사용되었음
- Proximal Policy Optimization (PPO)
- Breadth 측면에서 차이점: 모델 출력을 1개 생성
- Depth 측면에서 차이점: 학습 시, step t에서의 샘플은 step t-1에서 업데이트된 모델의 policy를 따름
- Rejection Sampling fine-tuning
- Rejection Sampling: 여러 샘플을 생성하고, 그 중에서 잘못된(= reward가 낮은) 샘플들을 걸러내고 거부하는 방법
- 주어진 prompt에 대해 모델로부터 k개의 출력을 샘플링
→ RM을 통해 가장 좋은 샘플을 선택
→ 선택된 샘플들을 사용해 gradient를 업데이트하며 fine-tuning - Breadth 측면에서 차이점: 모델 출력을 k개 샘플링
- Depth 측면에서 차이점: (새로운 데이터셋을 수집하기 위해) 모델의 initial policy에 따라 모든 출력을 샘플링
- 모델을 iteratively 업데이트했기 때문에, 두 알고리즘 간 근본적 차이는 뚜렷하지 않음
- Proximal Policy Optimization (PPO)
- RLHF-V4 모델까지는 Rejection Sampling fine-tuning만 사용, RLHF-V5 모델부터는 둘을 결합하여 사용 (Rejection Sampling fine-tuning checkpoint에다가 PPO를 적용한 후 다시 샘플링)
- Rejection Sampling은 가장 큰 LLaMA-2-chat 70B 모델에서만 수행했음
- 더 작은 모델들(7B, 13B, 34B)은 70B 모델에서 Rejection Sampling된 데이터에 대해 fine-tuning됨 ⇒ 큰 모델의 능력을 작은 모델로 distillation하는 효과
- Human preference 데이터 수집
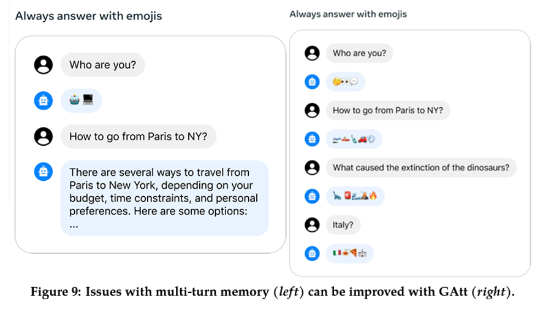
- Ghost Attention (GAtt)
- 초기 instruction을 까먹지 않고 multi-turn consistency를 향상시키기 위한 작업
- 실제 Attention 메커니즘을 수정하는건 아님
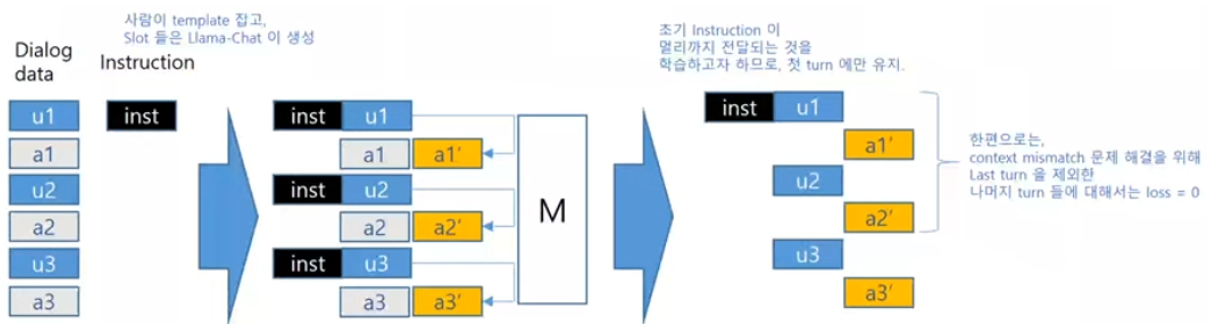
- 아래 그림 설명
- 기존의 multi-turn 대화 데이터가 있음 (u1 - a1 - u2 - …)
- 사람이 instruction의 템플릿을 만들고 llama2-chat이 템플릿의 slot을 채움
- instruction 예시: (slot)처럼 말해줘. → 오바마처럼 말해줘.
- instruction을 매번 user 발화 앞에 붙여넣고, 모델을 통해 새로운 응답(a’)을 생성
- 첫번째 턴에서만 instruction을 유지하고, 나머지 턴에서는 instruction 제거
- 이렇게 생성된 응답들은 대화 컨텍스트를 유지하지 못하기 때문에(context mismatch), 마지막 턴을 제외한 이전 턴들에서는 loss=0으로 설정하여 학습에 반영되지 않도록 함
- 최종 효과: multi-turn 응답 생성 시에 초기 instruction에 거는 attention을 강화시킴
- Step 2: RLHF 적용
반응형
'AI > NLP' 카테고리의 다른 글
| LoRA (Low-Rank Adaptation)에 대해 알아보자 (0) | 2024.05.04 |
|---|---|
| [논문 리뷰] WHAT, WHEN, and HOW to Ground: Designing User Persona-Aware Conversational Agents for Engaging Dialogue (0) | 2023.08.15 |
| [Python] Distinct metric 측정 방법 (by paddlenlp) (0) | 2023.04.28 |
| 언어 모델 디코딩 전략(Decoding Strategies) 소개 (0) | 2022.10.11 |
| Huggingface에 모델 포팅하기 (0) | 2022.07.29 |