
티스토리 뷰
[논문 리뷰] P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
체봄 2023. 8. 1. 19:09
이번에 리뷰할 논문은 "P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks"이다.
이는 ACL 2022에 short paper로 게재되었다.
본 논문에서 언급하는 기존 prompt tuning 연구의 한계점은 다음과 같다.
- 모델 크기가 작을 때(< 10B)에는 fine-tuning을 능가하지 못함
- 어려운 sequence labeling 태스크(ex: MRC, NER, SRL)에서는 fine-tuning을 능가하지 못함
본 논문의 contribution은 다음과 같다.
- properly optimized된 prompt tuning은 다양한 모델 크기와 NLU 태스크에서 fine-tuning 성능과 유사하다는걸 밝혀 냄
- Continuous prompts를 단지 input layer가 아니라 모든 layer들에 추가함
- Fine-tuning 대비 0.1~3.0%의 파라미터만을 사용

Lester et al. 의 논문은 우리가 익히 'Prompt-tuning'이라는 이름의 방식으로 알고 있는 "The power of scale for parameter-efficient prompt tuning" 논문이다. 본 논문에서는 Prompt-tuning, P-tuning, Prefix-tuning 등의 방식들을 모두 포괄하는 큰 개념을 'Prompt tuning'이라고 부르기 때문에, Lester et al. 의 논문은 본 논문에서 내내 'Lester et al.'로 표기된다.
그림을 살펴보면, Prompt-tuning 및 P-tuning에서는 첫번째 layer에만 continuous한 prompt를 추가하여 사용한다.
이렇게 되면 매우 적은 양의 tunable 파라미터를 사용할 수 밖에 없다. 또한, 첫번째 layer에만 prompt를 추가하여 tuning되기 때문에 이 prompt가 최종 prediction에 미치는 영향이 미미해진다.
이 그림이 본 논문에서 제안하는 P-tuning v2를 나타낸 것이다.
우선 이전 그림과 달라진 점은 prompt를 맨 앞에 추가하는 것이다.
또한 prompt를 첫번째 layer뿐만 아니라 모든 layer에 각각 추가한 것을 볼 수 있다. 각 layer마다 prompt를 hidden states와 이어붙여서 인코딩을 수행한다.
이로써 얻을 수 있는 효과는 tunable 파라미터 수가 많아졌기 때문에 task마다 더 많은 capacity를 가질 수 있으며, 파라미터 수가 늘어났음에도 여전히 fine-tuning 대비 0.1%~3% 정도로 효율적이다. 또한, 더 깊은 layer에 추가된 prompt는 최종 prediction에 더 직접적인 영향력을 가질 수 있게 되었다.
코드를 통해 prompt를 처리하는 내부 동작을 자세히 살펴보면 위 그림처럼 나타낼 수 있다.
우선 순차적으로 증가하는 인덱스의 prefix tokens을 만들고, Prefix Encoder를 통해 인코딩한다.
그런 다음 차원 변환 과정 (View → Permute → Split)을 통해서 layer 수만큼의 텐서를 얻는다. 이 텐서는 past_key_values로써 사전학습 모델에 전달된다. 이때 텐서의 0번째 차원이 2인 이유는 past_key_values라는 이름처럼 key에 대한 텐서와 value에 대한 텐서를 이어붙인 형태이기 때문이다.
사전학습 모델 내에서 각 layer마다 forward되는 과정에서는 다음의 작업이 이루어진다.
past_key_values로부터 현재 layer에 해당하는 텐서를 가져오고, key와 value를 분리한다. 각각은 오직 prompt에 대한 텐서이며, 차원은 (batch, n_head, prefix_seq_len, n_embd)이다. 다음으로 Self-Attention을 수행하기 위해서, key와 value의 뒷단에 hidden_states를 이어붙인다. 쉽게 말해서, query는 [hidden_states], key와 value는 [prompt; hidden_states]의 형태이다. 이후 attention을 수행하고 순차적으로 layer마다 인코딩이 진행된다.
- 코드 헤짚어보기 (순서대로)
- https://github.com/THUDM/P-tuning-v2/blob/main/model/multiple_choice.py#L159
- https://github.com/THUDM/P-tuning-v2/blob/main/model/prefix_encoder.py
- https://github.com/THUDM/P-tuning-v2/blob/main/model/token_classification.py#L155
- https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py#L588
- https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py#L496
- https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py#L427
- https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py#L276
- https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py#L378
- KP : Knowledge Probe
- SeqTag : Sequence Tagging
- Re-param: Reparameterization
- Deep PT : Deep prompt tuning
- No verb. : No verbalizer
기존 prompt tuning approach들과 P-tuning v2의 차이점을 나타낸 테이블이다.
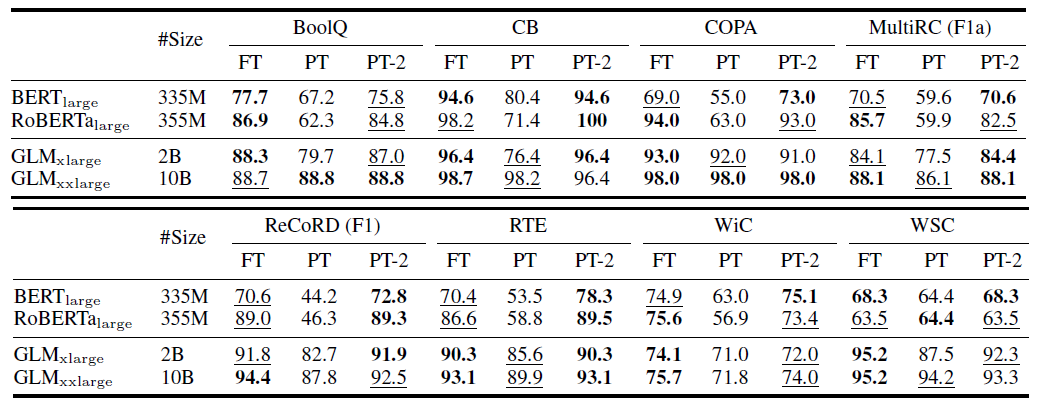
SuperGLUE 벤치마크에 대한 실험 결과를 나타낸 테이블이다. 모두 NLU 태스크이다.
핵심을 요약하자면 다음과 같다.
- PT (Prompt-tuning & P-tuning)은 작은 size의 모델에서 낮은 성능을 보임
- PT-2 (P-tuning v2)는 모델 size에 관계없이 FT(Fine-tuning)과 준하는 성능을 보임
- FT의 파라미터의 0.1%를 사용했음에도!
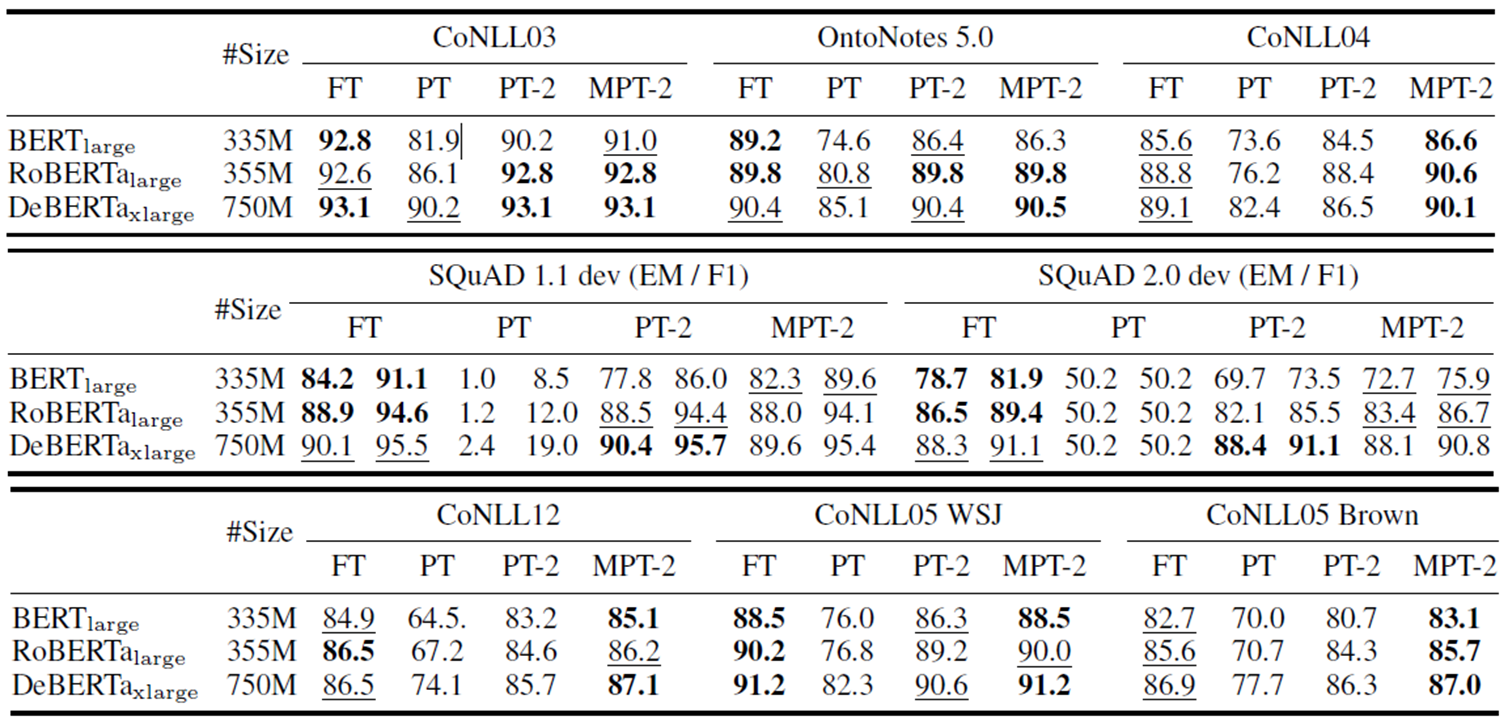
첫번째 표가 NER, 두번째 표가 MRC, 세번째 표가 SRL task에 대한 실험 결과이다.
핵심을 요약하면 다음과 같다.
- SQUAD 2.0에서 PT의 성능이 특히 낮은데, 이를 통해 single-layer prompt tuning으로는 no answer 질문을 optimize하는 데에 어려움이 있다고 분석함
- PT-2에 multitask learning을 적용한 MPT-2에서 대체적으로 성능이 향상됨
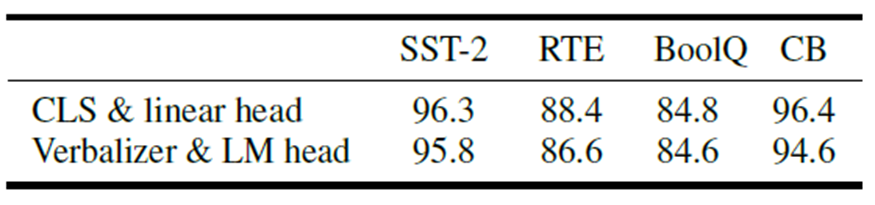
기존 prompt tuning 연구들에서는 보편적으로 LM head를 통한 verbalizer를 사용했는데, 이 방법이 sequence labeling task에 부적합함을 확인하였다고 한다.
따라서 본 논문에서는 randomly initialize된 classification head ([CLS] with linear head)를 사용하였고, Ablation Study를 통해 더 좋은 성능을 보임을 증명하였다. 또한, 기존에는 LM을 한번 더 거쳤던 작업을 linear layer만을 거치는 것으로 변경함으로써 효율성을 높였다.
그 외의 실험들을 간략히 언급한다.
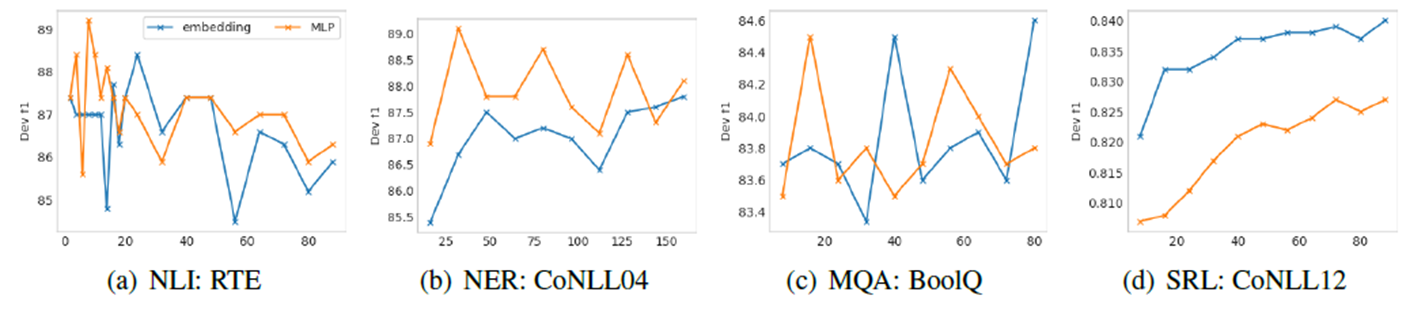
- 가로축: prompt length
- 세로축: F1 score
- (a)는 simple classification task, (b)/(c)/(d)는 hard sequence labeling tasks
기존 연구들은 보편적으로 더 안정적인 학습을 위해서 trainable embeddings에 MLP를 씌워 더 작은 차원으로 변환하는 reparameterization을 거쳤다 (주황색 그래프). 하지만, 본 논문에서는 reparameterization을 수행하는 것이 task나 데이터셋에 따라 효과적이지 않을 수 있음을 밝혔다.
또한, simple task에서는 prompt length가 짧은 것이 좋은 편이며, hard task에서는 prompt length가 긴 것이 좋은 편이라고 분석하고 있다.

Prompt를 descending order (output에 가까운 layer)로 추가하는 것과 ascending order (input에 가까운 layer)로 추가하는 것을 비교한 실험이다.
Descending order로 추가하는 것이 ascending order로 추가하는 것보다 우수함을 확인할 수 있다. 이는 당연히 예상할 수 있다시피, 더 깊은 layer에 prompt를 추가할 수록 모델의 예측에 더 직접적이고 큰 영향을 미칠 수 있기 때문일 것이다.
결론은 다음과 같다.
본 논문에서 제안한 P-tuning v2는 novel한 개념도 아니고 기술적인 독창성도 한정적이다. (저자들 스스로 인정함)
하지만 기존과 유사한 prompt tuning 방식을 적절하게 optimize함으로써, 모델의 크기나 task (NLU 한정)에 관계없이 fine-tuning에 준하는 성능을 내었다는 점이 본 논문의 contribution이다.
'AI' 카테고리의 다른 글
| KL-Divergence Loss (1) | 2023.12.23 |
|---|---|
| [Pytorch] nn.BCELoss(), nn.CrossEntropyLoss() (0) | 2023.04.12 |
| 모델의 특정 layer를 freeze시키기 (0) | 2023.02.02 |
| GPU id 지정하여 학습하기 (0) | 2022.06.06 |
| Neural Network 설명 및 직접 구현해보기 (0) | 2021.09.11 |