
티스토리 뷰
StarGAN 모델을 이용해 의류에 패턴을 합성하는 프로젝트를 진행하고 있다.
그래서 StarGAN에서의 기본 데이터셋인 사람 얼굴에 관련된 CelebA나 RaFD가 아닌, 의류에 관련된 커스텀 데이터셋을 사용하여 train 및 test하려고 한다.
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}우선 구글 드라이브와 연동하는 과정이다. 두번의 계정 인증이 필요하다.
cd /!mkdir -p Gdrive
!google-drive-ocamlfuse Gdrive
!ls Gdrivecd /Gdrive'/' 경로 아래에 'Gdrive'라는 폴더를 생성하고 이동한다. 이 폴더가 구글 드라이브 폴더이다.
!git clone https://github.com/yunjey/StarGAN.gitcd StarGAN/StarGAN repository를 clone하고 해당 폴더로 이동한다.
이 상태로 train하는 명령을 수행하면 'FileWriter'에 관련한 오류와 'Summary'에 관련한 오류가 뜨게 된다.
'FileWriter' 관련 오류를 미리 방지하기 위해 'logger.py' 파일의 9번째 줄에서 'FileWriter' -> 'create_file_writer'로 수정한다.
'Summary' 관련 오류를 방지하기 위해서는 'logger.py' 파일의 scalar_summary() 함수를 수정한다.
import tensorflow as tf
class Logger(object):
"""Tensorboard logger."""
def __init__(self, log_dir):
"""Initialize summary writer."""
self.writer = tf.summary.FileWriter(log_dir)
def scalar_summary(self, tag, value, step):
"""Add scalar summary."""
summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value)])
self.writer.add_summary(summary, step)기존 logger.py
import tensorflow as tf
class Logger(object):
"""Tensorboard logger."""
def __init__(self, log_dir):
"""Initialize summary writer."""
self.writer = tf.summary.create_file_writer(log_dir)
def scalar_summary(self, tag, value, step):
"""Add scalar summary."""
with self.writer.as_default():
tf.summary.scalar(tag, value, step)
self.writer.flush()수정 logger.py
StarGAN GitHub의 Readme에 따르면 커스텀 데이터셋으로 train과 test를 할 때는 RaFD 데이터셋을 사용할 때처럼 하면 된다고 한다.
CelebA 데이터셋만을 이용할 때에는 'list_attr_celeba.txt' 파일에 Labeling을 해줘야 하지만, RaFD 데이터셋만을 이용하는 경우에는 Labeling을 직접 해줄 필요 없이 'train' 폴더와 'test' 폴더를 만들어 하위에 attribute 별로 폴더를 만들고 그 안에 이미지를 저장하면 된다. 즉, 아래 링크에 나와 있는 구조대로만 폴더와 파일을 저장하면 된다.
github.com/yunjey/StarGAN/blob/master/jpg/RaFD.md
따라서 RaFD 데이터셋을 사용하는 방식으로 커스텀 데이터셋을 사용하면 되므로, 먼저 'StarGAN/data/custom' 폴더 하위에 'train', 'test' 폴더를 만든다.
내가 사용할 특성은 check, dot, flower, stripe이므로 'train' 폴더와 'test' 폴더 하위에 각각 'check', 'dot', 'flower', 'stripe' 폴더를 만든다. 그리고 각 특성에 해당하는 이미지들을 특성 폴더 안에 저장하면 된다.
train용 이미지는 90%, test용 이미지는 10% 정도로 비율을 맞추라고 하는데, 나는 그냥 동작을 확인하는 단계이기 때문에 test용 이미지는 한 특성당 10장 정도로 매우 적게 진행했다. 이 때, train용 이미지는 양이 많기 때문에 전처리를 해주기 힘들어 하지 않았지만, test용 이미지는 양이 적어서 전처리를 했을 때와 안 했을 때의 차이를 비교해보니 확실히 했을 때의 결과물이 더 좋았다. 전처리는 옷이 최대한 중앙에 위치하면서 256x256 크기로 resize해주었다.
이제 준비는 끝났고 train을 할 차례이다.
# Train StarGAN on custom datasets
!python main.py --mode train --dataset RaFD --rafd_crop_size 256 --image_size 128 --c_dim 4 \
--rafd_image_dir data/custom/train \
--sample_dir stargan_custom/samples --log_dir stargan_custom/logs \
--model_save_dir stargan_custom/models --result_dir stargan_custom/results이미지 크기를 128x128로 설정하고, c_dim은 특성의 수를 의미하므로 4로 설정하였다.
학습이 진행되면서 총 200000번의 iteration을 도는데 10000번마다 model이 저장된다. 이 model이 저장되는 경로가 'stargan_custom/models'이다. 'x0000-D.ckpt', 'x0000-G.ckpt' 파일이 생성된다.

...

29400번째 iteration에서 세션이 끊겨서 학습이 중단되었다. 세션을 다시 연결해서 해보면 이어서 학습할 수는 없다.
10000번 iteration을 수행해 하나의 model이 생성되는 데에 3시간 정도 걸린 것 같다. 학습을 처음부터 다시 시작하는 건 말이 안되는 상황이라 20000번째 iteration에서 생성된 model을 사용해 test를 해보기로 했다.
test하는 명령은 다음과 같다.
# Test StarGAN on custom datasets
!python main.py --mode test --dataset RaFD --image_size 128 \
--c_dim 4 --rafd_image_dir data/custom/test \
--sample_dir stargan_custom/samples --log_dir stargan_custom/logs \
--model_save_dir stargan_custom/models --result_dir stargan_custom/results여기서 또 문제가 발생한다.
train 과정에서 총 iteration 수가 200000으로 설정되어 있기 때문에 test할 때에는 가장 마지막 iteration인 200000번째에서 생성된 model을 찾는다. 즉, '200000-D.ckpt', '200000-G.ckpt' 파일을 찾는데, 나는 10000번째와 20000번째 모델밖에 없기 때문에 에러가 발생한다. 이를 해결하기 위해 '20000-D.ckpt'와 '20000-G.ckpt' 파일의 이름을 '200000-D.ckpt'와 '200000-G.ckpt'로 변경하여 다시 컴파일 하였더니 test가 잘 수행되었다.
'test' 폴더에 저장한 이미지의 수에 거의 비례하여 결과 이미지들이 'stargan_custom/results' 폴더에 생성된다.
결과물의 순서는 원본-체크-도트-꽃무늬-줄무늬 이다.
결과물1) test 이미지에 패턴 의류를 전처리 없이



원본 이미지를 직접 전처리 해주지 않았기 때문에 프로그램 상에서 전처리가 일어나는 과정에서 의류가 확대된 것과 같은 현상이 발생하여 의류의 완전한 모양에 합성을 할 수 없다.
결과물2) test 이미지에 흰색 의류를 200x200로 전처리



결과물1에서 볼 수 있듯이, test 이미지를 고유의 패턴을 가지는 의류로 하면 고유 패턴과 합성하려는 패턴이 합쳐져 잘 합성이 되지 않는다. 그래서 train 과정에서 어차피 패턴을 학습하고, test 과정에서 옷에 패턴을 입히는 것이기 때문에 test 이미지를 패턴 의류가 아닌 흰색 의류로 하면 더 깔끔하게 합성이 되지 않을까 싶어 흰색 의류에 대해 테스트해보았다.
결과물은 아주 처참했다. 합성이 된건지 안된건지 모를 정도다. 패턴 의류를 사용하는게 맞는 것 같다.
결과물3) test 이미지에 흰색 의류를 256x256로 전처리



결과물2에서 200x200으로 전처리했기 때문에 이미지가 너무 작아서 결과가 안 좋은게 아닐까 하는 생각에 256x256으로 전처리하여 흰색 의류에 대해 한번 더 해봤지만 결과물은 거의 비등했다. 패턴 의류에 대해서 해야겠다.
결과물4) test 이미지에 패턴 의류를 256x256으로 전처리
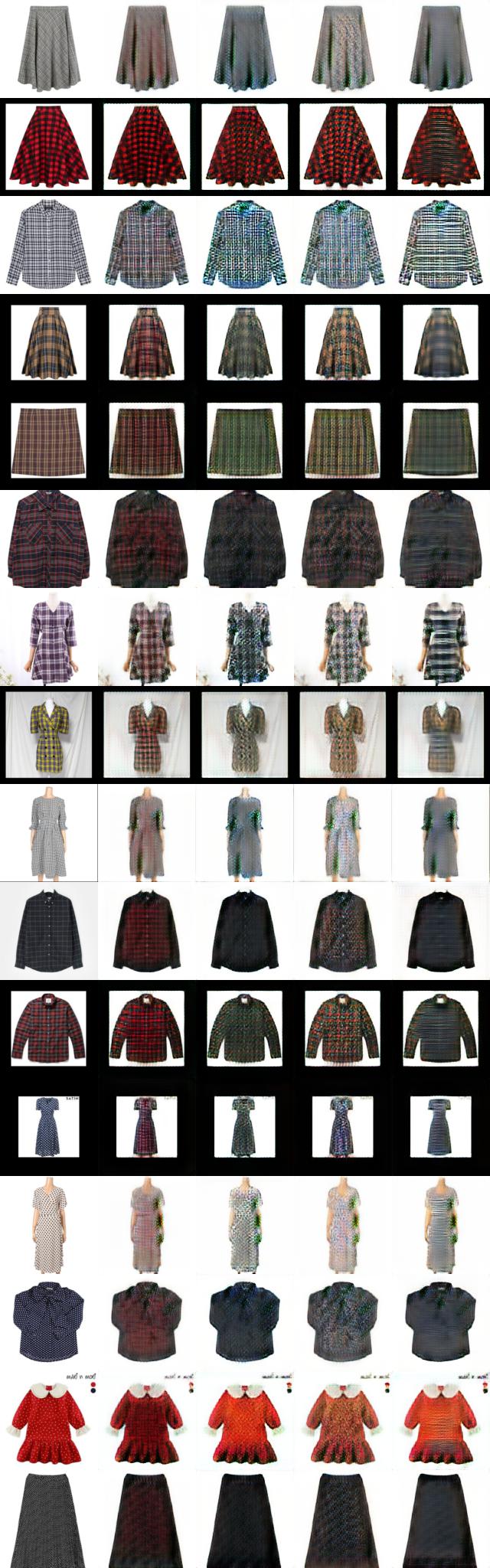



여태까지의 결과물 중에 가장 나은 결과물이 나왔다.
체크는 많은 경우에서 체크 무늬인 것을 알 수 있을 정도이다. 줄무늬도 가로 줄로 패턴을 합성하려는 조짐이 꽤 보인다. 하지만 도트와 꽃무늬는 전혀 안나온다고 봐도 무방하다. 꽃무늬의 경우 꽃무늬 패턴이 너무나 다양하기 때문에 훨씬 많은 학습이 필요할 것 같다.
'AI > Computer Vision' 카테고리의 다른 글
| [StarGAN] 코드 파악하기 - solver.py (1) (0) | 2021.01.09 |
|---|---|
| [StarGAN] 코드 파악하기 - model.py (0) | 2021.01.07 |
| [StarGAN] 코드 파악하기 - main.py (0) | 2021.01.04 |
| [StarGAN] pre-trained 모델로 커스텀 데이터셋 test하기 (0) | 2020.12.28 |
| DeepFashion2 dataset 다운로드 방법 (0) | 2020.07.17 |