
티스토리 뷰
[퀀트 전략 파이썬으로 세워라]라는 책을 참고하여
Python 3.7 환경에서 마법 공식(Magic Formula)를 이용하여 주식 분석을 해보겠습니다.
코드를 실행하기에 앞서, 작업하려는 폴더 아래에 'magic_formula_data.xlsx' 파일을 저장합니다. 이 파일에는 기업들의 PER값과 ROA값이 저장되어 있습니다.
파일을 열어보면 다음과 같습니다.


그런 다음 이 파일을 tensorflow가 설치되어 있는 Python 3 환경의 Jupyter Notebook에서 실행하겠습니다.

우선 엑셀을 읽어오는 모듈인 xlrd를 import해줍니다. 설치되어 있지 않다면 미리 Anaconda Prompt에서 pip install xlrd 명령을 통해 설치해줍니다.
그런 다음 xlrd 모듈의 open_workbook 함수를 통해 주가 데이터가 저장되어 있는 엑셀 파일을 읽어 옵니다.


wd는 엑셀 파일 전체를 나타내고 있습니다. 우선 PER 순위만을 구할 것이므로 sheet_by_name 함수를 통해 'PER' 시트만을 읽어와 per_sh에 저장합니다.
for문에서는 PER 시트로부터 한 줄씩 읽어와 회사명과 PER 값을 저장하는 동작이 수행됩니다.
per_sh로부터 한 줄을 읽어오면 data에는 회사명과 PER 값이 차례대로 저장됩니다. 그러므로 data[0]은 회사명을, data[1]은 PER 값을 나타내겠죠?
주식 분석을 할 때에는 PER 값이 양수인 데이터만 필요합니다. 따라서 PER 값이 양수인 경우에만 key는 name, value는 per로 하여 per_dict 딕셔너리에 저장해줍니다.

그리고 per_dict 딕셔너리를 출력해보면 key에는 회사명이, value에는 해당 PER 값이 잘 저장된 것을 확인할 수 있습니다.

여기서 사용되는 엑셀 파일에서는 회사명이 오름차순으로 정렬이 이미 되있어서 굳이 정렬을 해주지 않아도 되지만, 이렇게 sorted 함수를 통해 이름을 정렬할 수 있습니다.
sorted 함수를 사용함으로써 딕셔너리 형태였던 per_dict가 리스트 형태로 바뀐 것을 확인할 수 있습니다.

정렬된 per_dict 리스트를 items() 함수를 통해 확인해보면 이와 같습니다. 딕셔너리에서의 key와 value가 튜플 형태로 순서대로 저장되었습니다.

PER 값은 작을 수록 좋은 값입니다. 그러므로 PER 값이 작은 순서대로 정렬을 해보겠습니다.
operator 모듈이 설치되있지 않다면 Anaconda Prompt에서 pip install operator 명령을 통해 미리 설치해줍니다.
value 값들을 기준으로 정렬하기 위해 operator 모듈을 import합니다.
이전 캡처에서 items() 함수를 실행했을 때, item이 회사명과 PER 값 순서로 저장되어 있는 걸 확인했었는데요. operator.itemgetter(1)는 1번째 item을 가져온다는 의미입니다. 기본적으로 0번째부터 시작이므로 0번째 item이 회사명, 1번째 item이 PER 값을 가리키는 것이죠.
따라서, sorted 함수는 기준 key를 PER 값으로 하여 per_dict의 item들을 오름차순으로 정렬하는 것입니다.
sorted_per의 출력 결과를 보면 PER 값이 작은 순서대로 정렬된 것을 확인할 수 있습니다.

우리가 구하려는 것은 PER 값만을 봤을 때 기업들의 순위입니다.
sorted_per 리스트에 이미 PER 값이 작은 순서대로 정렬을 해두었으니 이를 이용해 순위를 하나씩 매길 것입니다.
이를 위해서는 per_rank라는 새로운 딕셔너리를 만들고, PER 값이 낮은 순서대로 sorted_per의 데이터를 가져오면서 회사명을 key로 하고 value를 1부터 하나씩 증가시키며 per_rank에 저장하면 됩니다.
그렇게 하여 저장된 per_rank 딕셔너리를 출력해보면 sorted_per에서 PER 값을 나타내던 부분이 순위로 바뀌어 저장된 것을 확인할 수 있습니다.
PER 순위를 구하기가 완료되었습니다.

주식 분석을 할 때에는 ROA 값이 존재하는 데이터만 필요하며, ROA 값은 클 수록 좋은 값입니다.
이 점을 제외하고는 1. PER 순위 구하기 와 과정이 동일하므로 생략하겠습니다.

가장 좋은 주식을 판별하기 위해 PER 순위와 ROA 순위 구한 것을 바탕으로 Total 순위를 구할 것입니다.

우선 따져야 할 것은 PER 순위를 구한 per_rank와 ROA 순위를 구한 roa_rank에 모두 존재하는 회사여야 한다는 것입니다.
그리고 total_rank 딕셔너리에 PER 순위 값과 ROA 순위 값을 더하여 value로 저장합니다.

total_rank를 출력해보면 두 순위를 더하였기 때문에 value 값이 크게 나옵니다.
전체 순위를 구하기 위해 value 값이 작은 순서대로 다시 한번 순위를 매겨보겠습니다.
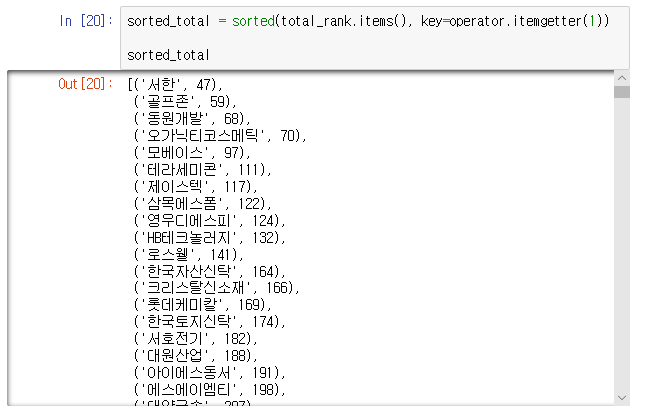
total_rank의 value 값을 기준 key로 하여 total_rank를 오름차순으로 정렬하여 sorted_total에 저장합니다. value값이 작은 순서대로 정렬이 되었습니다.
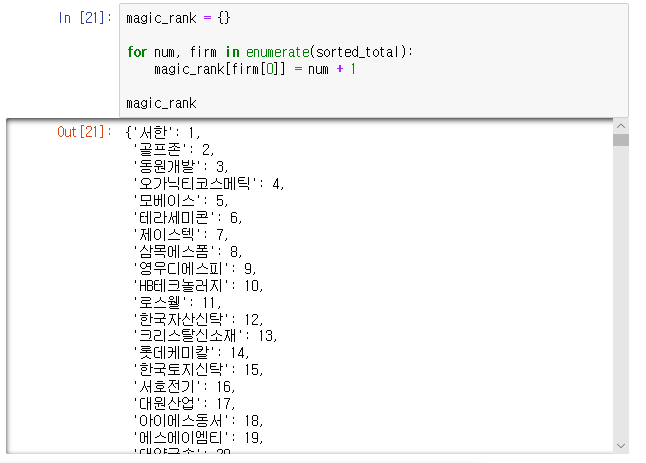
sorted_total에 저장된 순서대로 value 값을 1부터 하나씩 증가시키며 순위를 매깁니다.
이렇게 최종 순위를 매기는 것까지 완료하였습니다.
주어진 데이터 파일을 기반으로 했을 때, 최종적으로 주가가 가장 높은 기업은 '서한'이 되겠습니다!
마법 공식을 이용한 주식 분석, 어렵지 않죠? :)
초보자라 틀린 부분이 있을 수 있습니다. 틀린 부분은 댓글 남겨주시면 감사하겠습니다!
'AI > NLP' 카테고리의 다른 글
| KoNLPy-gRPC API 사용하기 (0) | 2021.02.06 |
|---|---|
| [NLP] 기초 개념 필기 (0) | 2020.12.18 |
| [NLP] 구글 Colab에서 Mecab 설치와 사용법 (+파이썬 연동) (1) | 2020.01.27 |
| [NLP] word2vec 사용해보기 (0) | 2020.01.13 |
| [Windows] KoNLPy 설치하기 및 사용법 (0) | 2020.01.06 |