[논문 리뷰] WHAT, WHEN, and HOW to Ground: Designing User Persona-Aware Conversational Agents for Engaging Dialogue
"WHAT, WHEN, and HOW to Ground: Designing User Persona-Aware Conversational Agents for Engaging Dialogue"라는 제목의 이 논문은 ACL 2023 Industry Track에 게재되었고, SK Telecom에서 작성한 논문이다.
Personalize된 오픈 도메인 대화 시스템에서 응답 생성 시에 발생하는 WHAT, WHEN, HOW 문제를 해결하기 위한 방법을 제안하고 있다.
데이터셋 중점의 방법론을 제안하고 있으며, response-type label 생성을 통해서 확장된 효과를 취했다.
1 Introduction

Personalized dialogue (PD) system에서는 일반적으로 주어진 페르소나 셋에서 현재 대화 내용과 관련 있는 페르소나를 선택해서 응답에 활용해야 한다 (Figure 1의 첫번째 bot 응답). 대화 컨텍스트가 주어졌을 때, 어떤 페르소나를 선택할지 결정해야하는 이 문제를 본 논문에서는 "WHAT (to ground)"라고 일컫는다.
PD system에서 고려해야 하는 또 다른 측면은, 어떤 경우에는 personalized response가 아닌, 대화 컨텍스트에 따른 casual response를 하는 것이 자연스럽다는 점이다 (Figure 1의 두번째 bot 응답). 이는 다시 말해, 응답을 할 때 언제 페르소나를 기반으로 활용할지를 판단해야하는 문제이며 본 논문에서는 "WHEN (to ground)"라고 지칭한다.
그리고 페르소나를 기반으로 응답을 할 때, 어떻게 더욱 자연스러우면서 사람 같은 응답을 만들 수 있을지에 대한 challenge를 "HOW"라고 지칭한다.
이 "WHAT", "WHEN", "HOW" 문제를 통칭하여 WWH라고 부른다.
대부분의 PD system 연구에서는 이상화된 personalized 대화 환경, 즉 관련 있는 페르소나를 더 잘 선택하고 잘 반영해 응답하는 데에 초점을 맞췄다. 그런데, 대화 응답에 personalized response가 너무 많이 등장한다는 점은 고려되지 않고 있다. ("WHEN" 문제가 고려되지 않고 있다는 의미로 이해했다.) 저자들은 real-world 대화 시스템에서는 이 문제가 꼭 해결되어야 할 중요한 문제라고 생각한다고 한다.
LLM (Large-scale Language Models)이 다양한 NLU 태스크에서 in-context learning을 통해 뛰어난 성능을 보여주고 있지만, LLM에 내재된 능력만으로는 까다로운 WWH 문제를 해결하기에 충분하지 않다고 한다.
따라서, 본 논문에서는 personalized response를 생성하는 모델의 경향을 제어하기 위해, 다음 단계의 접근 방식을 제안한다:
- Multi-Session Personalized Conversation (MSPC) 데이터셋을 구축하였다. 이를 이용해 모델이 효과적으로 페르소나 기반의 응답을 생성하도록 학습시킨다.
- 여러 대화 데이터셋들의 weight blending을 통해서 모델의 persona-grounding 정도를 제어한다. 또한, 턴마다 negative persona subsets을 추가함으로써 데이터셋을 풍부하게 한다.
- 턴마다 생성해야 하는 응답이 personalized인지 또는 casual인지를 나타내는 turn label을 사용한다.
18B 크기의 LLM을 fine-tuning함으로써 personalized dialogue system을 구축한다.
2 Related Work
PersonaChat 데이터셋이 공개된 후로, 페르소나 기반의 응답을 생성하기 위해 광범위한 연구들이 진행되었다. 대부분의 연구는 "WHAT", "HOW" 문제를 해결하는 데에만 초점을 둔다.
그러나, 저자들이 아는 한, PD system에서 "WHAT", "WHEN", "HOW" 문제를 모두 해결하려는 연구는 없었다. WWH 문제를 모두 해소하는 것은 상업 시스템에서 필수적이기 때문에 이를 위한 새로운 방식을 제안한다.
3 Dataset
WWH 문제들을 해결하는 PD system을 만들기 위해, 한국어 Multi-Session Personalized Dialogue (MSPD) 데이터셋을 구축했다.
이 데이터셋의 목적은 모델이 persona-grouding에 있어서 "WHEN"과 "HOW"를 배울 수 있게 하는 것이다.

Table 4에 따르면, 평균적으로 한 episode당 4개의 sessions가 존재하고, 각 session은 11 turns로 구성된다.
"WHEN"과 "HOW" 문제를 데이터셋 관점에서 해결하기 위해서, 세션당 personalized response의 수를 2개 이하로 제한하였다. 그리고 personalized response의 품질과 적절성을 확실하게 하기 위해 엄격한 검토를 수행했다.

Figure 3의 왼쪽 Conversation에서 빨간색으로 표시된 발화는 user persona를 기반으로 agent가 한 응답을 의미하고, 파란색으로 표시된 발화는 user persona를 기반으로 user 자신이 한 응답을 의미한다. 빨간색/파란색 발화 뒤에 대괄호 안에 표시된 것은 User Persona Attributes 중에서 기반으로 활용한 페르소나의 인덱스 또는 user에 관한 기억할만한 personal information을 annotation한 것이다. 후자의 경우 이는 다음 session에서 User Persona Attributes에 새롭게 추가된다.
또한, 저자들은 $D_{casual}$로 표기되는 다양한 일상 대화 데이터셋들을 통합해 사용하는데, 이는 일상, 지식, 공감, 페르소나 기반의 대화를 모델이 모두 잘 할 수 있도록 학습하기 위함이다. AiHub에 공개된 데이터셋들 및 PersonaChat, EmpatheticDialogues, Wizard of Wikipedia (이 세가지는 BlendedSkillTalk 데이터셋을 구성하는 데이터셋들이다)의 한국어 버전 데이터셋들을 통합하여 사용했고, 총 1250만개의 발화들로 구성되는 방대한 데이터셋이다.
4 Methodology
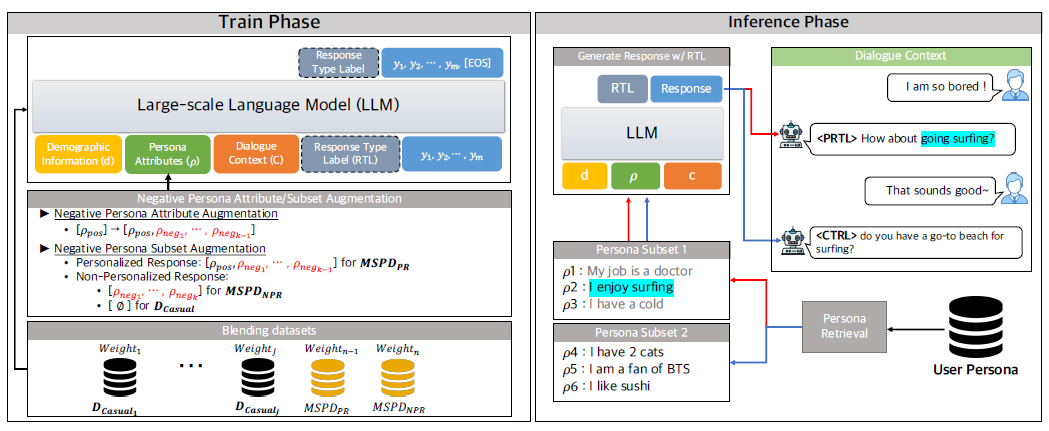
Training Phase에서는 "WHAT", "WHEN" 문제를 해결하기 위해 다양한 방법 (negative persona augmentation, dataset blending, response type generation)을 사용한다.
Inference Phase에서는 Demographic information of user ($d$), Persona Subset of user ($p$), Dialogue Context ($c$)가 입력으로 LLM에 제공된다. 이때, Persona Subset은 User Persona attributes 메모리로부터 대화 컨텍스트와 관련 있는 것을 검색해온 것이다. 그러면 LLM은 Response Type Label (RTL) 및 Response를 출력한다.
4.1 Persona-Grounded Generation
모든 학습 데이터는 demographic information of user $d$ (ex: 성별, 나이), persona subset of user $p^m$ (persona attribute들로 구성됨), dialogue context $c^m=[u_1,a_1,...,u_{m-1},a_{m-1},u_m]$, 그리고 target response $y^m$로 구성된다.
$(d, p^m, c^m)$이 입력으로 주어지면, 다음의 조건부 확률 및 NLL loss로 모델을 optimize한다.
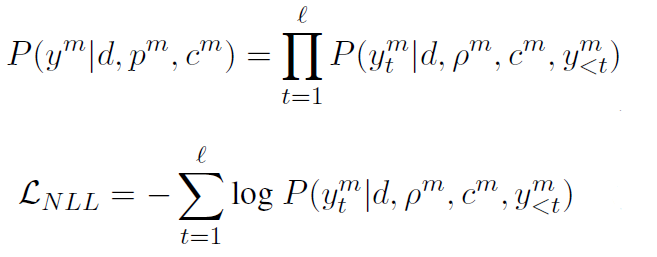
4.2 Dataset Blending
(Smith et al., 2020)에서는 다양한 대화 데이터셋들을 blending하는 것이 모델의 다양성, 공감, 지식 수준을 향상시키며 자연스럽고 engaging한 대화로 이끈다는 것을 보여주었다. 그래서 본 논문에서는 Dataset Blending을 수행한다.
이를 수행하기에 앞서, MSPD 데이터셋은 agent가 personalized response를 하는 $D_{MSPD-PR}$과 non-personalized(=casual) response를 하는 $D_{MSPD-NPR}$ 데이터셋으로 분리된다.
그런 다음 $D_{MSPD-PR}$, $D_{MSPD-NPR}$ 및 $D_{casual}$의 각 데이터셋마다의 weight에 따라서 인스턴스별 blending을 수행한다. 학습 데이터로 사용될 개별 데이터셋의 크기는 각 데이터셋의 weight를 기반으로 다음 수식에 따라 산정된다.
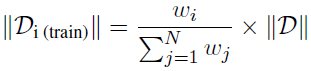
4.3.1 Control of WHEN by Negative Samples
"WHEN" 문제와 관련하여, 페르소나 기반의 응답을 너무 빈번하게 생성하면 대화가 부자연스러워지고, 반대로 너무 드물게 생성하면 engaging한 대화가 어려워진다.
각 턴마다 대화 컨텍스트와 관련 있는 persona subset이 검색되는 상황이지만, 대화 내용에 따라 personalized response가 아니라 casual response를 생성할 수 있어야 한다.
따라서 non-personalized response를 생성하는 법을 학습시키기 위해, 대화 컨텍스트와 관련이 없는 persona attributes로만 구성된 persona subset을 추가하였다. 이 과정을 negative persona subset augmentation이라고 부른다.
하지만 이 과정을 과도하게 수행하면 모델의 persona-grounding 능력이 저해될 수 있으므로, 이 과정은 $D_{MSPD-NPR}$ 데이터셋에 대해서만 수행한다.
4.3.2 Control of WHAT by Negative Samples
다음으로 "WHAT" 문제에서는 주어진 페르소나들 중에 어떤 페르소나를 기반으로 응답할지를 판단해야 한다.
이를 위해, target response와 관련이 있는 ground-truth persona attribute $p_{pos}$에다가 관련이 없는 negative persona attributes $p_{neg1}$, ..., $p_{neg(k-1)}$를 추가하여 하나의 persona subset으로 구성해 모델에 제공한다.
그러면 모델은 주어진 persona subset에서 현재 대화 컨텍스트에 적절한 persona attribute(s)를 선택하는 법을 학습하게 된다.
이 과정을 negative persona attribute augmentation이라고 부른다.
이 과정은 $p_{pos}$가 존재해야하므로, $D_{MSPD-PR}$ 데이터셋에 대해서만 수행한다.
최종적으로, negative persona subset/attribute augmentation을 수행한 후의 persona subset $p$는 다음과 같이 구성된다.
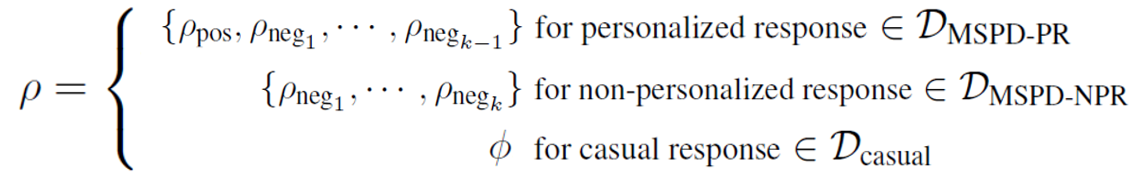
4.4 Controllability & Explainability via Response Type Label
"WHEN" 문제를 해소하기 위해, Response Type Label (RTL)을 활용함으로써 모델의 결정을 명시적으로 제어한다.
RTL의 종류로는 Personalized RTL을 의미하는 $<PRTL>$과 Casual RTL을 의미하는 $<CRTL>$ 스페셜 토큰을 사용한다.
Training Phase에서는 $P(<RTL>,y|d,p,c)$와 같이 RTL 토큰과 response를 생성하도록 모델을 학습시킨다.
Inference Phase에서는 $P(y'|d,p,c,<RTL>)$와 같이 RTL 토큰을 입력으로 줄 수 있고, 모델은 이에 해당하는 type의 response를 생성한다.
뿐만 아니라, RTL은 모델이 생성한 응답에 대한 설명 가능성을 향상시키는 역할도 한다. 이는 에러 분석을 더 용이하게 한다.
5 Experiments
Baselines
- GPT-3와 동일한 아키텍쳐를 갖는 사내 18B pre-trained LM으로부터 파생된 모델들을 사용
정량 평가 지표
- Perplexity (⇒ 응답의 fluency를 측정)
- F1 score between generated response and persona attributes (⇒ 모델의 grounding 능력을 평가하는 역할을 함)
- P-coverage (⇒ 생성된 응답에 페르소나가 얼마나 잘 반영되었는지를 측정)
정성 평가 지표
- Session Turn Evaluation
- Session-level에서는 Session Score를 평가
- Turn-level에서는 Sensibleness와 Specificity를 평가 (0/1)
- Grounding Evaluation
- Turn-level로 생성된 응답이 personalized response인지 아닌지를 먼저 평가
- 생성된 응답을 ground-truth 페르소나와의 grounding level에 따라 분류
- Hard Grounding: 직접적이고 명시적인 관련이 있는 경우
- Soft Grounding: 간접적이고 내재적인 관련이 있는 경우
- 생성된 응답을 ground-truth 페르소나와의 consistency 여부에 따라 분류
- Consistent Grounding: 일관성이 있는 경우
- Inconsistent Grounding: 일관성이 없는 경우

우선 Positive persona attribute로만 학습한 Model1에서는 PPL 점수가 가장 안 좋고, F1 점수는 가장 좋은데 그 이유는 페르소나를 항상 기반으로 응답하도록 학습되었기 때문이다.
여기에 Negative Persona Attributes Augmentation을 수행한 Model2에서는 PPL 점수가 개선되었고, F1 점수는 하락하였다. 이는 grounding 빈도는 감소하였지만 응답 생성 품질은 향상되었다는 것을 의미한다.
여기에 Negative Persona Subset Augmentation을 수행한 Model3에서도 유사한 양상을 보였다. 해당 method를 통해서 "WHEN" 문제를 해소, 즉 관련 없는 페르소나를 grounding하는 경우가 줄어들었기 때문으로 분석된다.
여기에 RTL을 생성하는 작업을 추가한 Model4에서는 가장 우수한 PPL 점수를 보였다. 이는 target response와 연관된 정보를 동시에 생성할 때, 응답 생성 품질이 향상된다는 Kim et al. (2022)의 연구 결과와 일관되는 결과이다.
추가적으로, 생성된 RTL이 persona grounding에 대한 모델의 결정을 정확하게 반영하는지(= explainability)에 대한 평가를 진행했다. 각 response type에 대해서 90개의 생성된 응답을 샘플링하여 평가했다.
Personalized RTL과 Casual RTL이 생성되었을 때의 accuracy는 각각 98.8%, 96.7%로 굉장히 높은 수치를 보여준다.
따라서 RTL을 생성하는 것은 "WHEN" 문제에 관한 모델의 결정에 대해서 신뢰 가능한 설명을 제공한다.
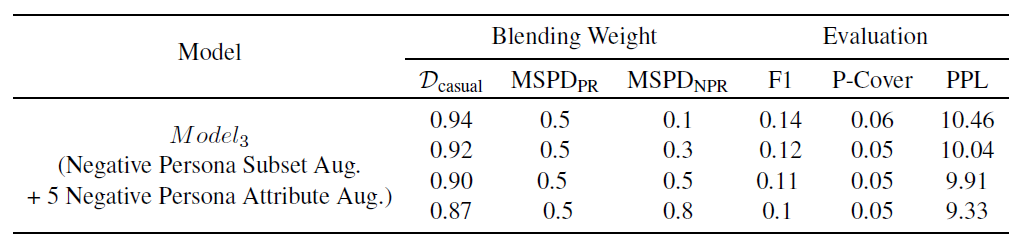
모델의 fluency (= PPL)와 grounding tendency (= F1) 간에는 trade-off가 존재한다.
Negative Persona Subset으로 구성된 $MSPD_{NPR}$의 Blending Weight를 증가시킬수록, F1 및 P-Coverage 점수는 떨어지고 PPL 점수는 개선된다. 이는 다시 말해, negative sample의 수가 많아질수록 모델은 persona grounding을 덜 하게 되고, 더 자연스러운 응답을 하게 된다.
F1 점수가 1 미만인 모델의 경우 persona grounding을 거의 하지 않는다는 것을 일관되게 관찰했기 때문에, F1 점수의 최소 threshold를 1로 설정했다. (이 부분은 명확히 이해가 되지 않았다.)

두 모델에서 모두 볼 수 있듯이, Hard Grounding을 한 인스턴스가 Soft Grounding 인스턴스보다 4배정도 많았다.
- Model3에서 Hard Grounding 인스턴스 162개, Soft Grounding 인스턴스 41개
- Model4에서 Hard Grounding 인스턴스 125개, Soft Grounding 인스턴스 35개
bad-sensible, 즉 Sensibleness 점수가 낮은 응답도 10% 이내로 매우 적은 편이다.
Model4를 Model3과 비교했을 때, persona grounding 경향성은 조금 낮아졌지만 bad-sensible 응답의 비율은 더 개선되었다. 따라서, response와 함께 RTL을 생성하는 것은 fluency 향상에 효과적임을 확인할 수 있다.
Conclusion
본 논문에서는 personalized 오픈 도메인 대화 시스템에서 더 자연스럽고 매력적인 대화를 위해 WWH 문제를 해결하기 위한 방법들을 제안했다. 정량 평가 및 정성 평가를 통해 그 효과를 입증했다.
- For WHEN challenge
- Weighted Dataset Blending, Negative Persona Subset Augmentation, RTL generation
- For WHAT challenge
- Negative Persona Attribute Augmentation
- For HOW challenge
- 고도로 엄선한 MSPD 데이터셋 구축