AI/NLP
[BlenderBot 2.0] Beyond Goldfish Memory: Long-Term Open-Domain Conversation 논문 리뷰
체봄
2022. 4. 6. 23:43
논문 링크: https://arxiv.org/abs/2107.07567
Beyond Goldfish Memory: Long-Term Open-Domain Conversation
Despite recent improvements in open-domain dialogue models, state of the art models are trained and evaluated on short conversations with little context. In contrast, the long-term conversation setting has hardly been studied. In this work we collect and r
arxiv.org
Abstract
- 현재 SOTA 모델들은 context가 거의 없는 짧은 대화에 대해 학습 및 평가된다
- 장기적인 대화에 있어서는 거의 연구가 되지 않고 있으며 현존하는 모델의 성능이 저조하다
- 우리는 발화자들이 서로의 관심사를 알아가고 과거 세션에서 그들이 배운 것에 대해 토론을 하는 채팅 세션들로 구성된 인간-인간 데이터셋을 공개한다
- retrieval-augmented 방법 및 이전 대화를 요약 및 회상하는 능력을 갖춘 방법이 표준 인코더-디코더 구조를 능가한다
1 Introduction
- 큰 신경망 언어 모델을 학습시킬 수 있게 되고, 크면서 고품질인 대화 데이터셋이 이용 가능해짐에 따라 오픈도메인 대화 모델의 개발에 박차를 가하고 있다
- But, 현재 놓치고 있는 중요한 사항은 인간의 대화는 오랜 시간동안 일어날 수 있지만 현재 사용되는 시스템에서는 어렵다는 점
- 일반적으로 사용되는 학습 및 평가 리소스는 학습 examples의 수는 많지만 2~15턴의 짧은 대화로만 구성되어 있고, single-session으로 구성되어 있다
- 그래서 현재 SOTA 모델들(ex: Meena, BlenderBot(2020))은 토큰 truncation 길이가 겨우 128 토큰인 Transformer를 사용함
- 이들은 장기적인 대화 context를 통합할 수 없을 것이고, 길거나 multi-session인 대화도 잘 수행하지 못할 것
- 우리는 장기간의 오픈도메인 대화를 위한 방법을 연구한다
- Multi-Session Chat (MSC) 데이터셋을 만들어 공개한다
- 인간-인간 크라우드 워커 채팅
- 5개 세션으로 구성, 각 세션은 최대 14개의 발언으로 구성
- 대화 상대는 몇 시간 또는 며칠 후에 다시 참여하여 채팅을 계속함
- 이전 세션에는 이후 대화에서 유용할 수 있는 개인의 중요한 점들이 요약되어 있다
- 2가지의 긴 컨텍스트 대화 아키텍처를 연구한다
- Retrieval-augmented generative models (RAG)
- 즉석에서 대화를 요약하고 저장하는 읽기-쓰기 메모리 기반 모델
2 Related Work
- 최근의 SOTA 오픈도메인 대화 agent들은 다음과 같은 데이터셋을 사용한다 -> Daily Dialogue, PersonaChat, Empathetic Dialogues, Wizard of Wikipedia, Pushshift.io Reddit
- 아래 표를 보면 알 수 있듯이 이 데이터셋들은 발화의 길이가 짧은 편이고 모두 single-session이며, 에피소드 당 발화의 수도 적은 편이다
- Multi-Session Chat이 이 논문에서 새로 공개한 데이터셋

- 표준 Transformers는 고정된 context 길이를 갖는다
- 크기가 매우 클 때 self-attention 매커니즘이 비효율적이기 때문
- 그래서 많은 사전학습 모델은 토큰 truncation 길이를 짧게 갖는다
- BlenderBot(2020), Meena는 128 토큰, BART는 1024 토큰
- self-attention 매커니즘의 속도를 높이기 위한 Long-context Transformers이 나옴
- retrieval-augmented 방법
- 고려된 토큰 집합에 보관할, context에서 관련있는 부분을 선택하는 방법을 고려한다
- 메모리 네트워크와 neural QA에서의 이전 방법들과 연결될 수 있는 고려된 토큰 집합
3 Multi-Session Chat
- 장기적인 대화에 대한 연구를 위해 우리는 모델을 학습 및 평가할 데이터가 필요하다
- 하나의 긴 single 대화로 이루어진 대화 셋을 수집하는 것보다, 여러 세션으로 대화하는 자연스러운 경우를 고려한다
- 각 채팅 세션은 얼마 되지 않아 일시정지 상태가 되고, 일정 시간(몇 시간 또는 며칠) 후에 대화를 다시 이어가도록 한다
- 대화를 이어갈 때는 이전 주제에 대해 계속 얘기하거나, 과거의 공유된 히스토리로부터 다른 주제를 꺼내거나, 아예 새로운 주제를 꺼낸다
- 이러한 multi-session 장기 대화 셋업을 고려하여 데이터셋을 Multi-Session Chat (MSC) 라고 명명한다

- 크라우드 워커를 고용해 개방형 채팅에 참여하도록 하였다
- 페르소나
- 크라우드 워커들은 그들 자신의 성격에 대해 말하는 것이 아니라, 부여받은 역할을 수행한다
- 역할은 그들이 연기하는 캐릭터의 특성, 사건, 견해를 설명하는 일련의 문장들로 주어진다
- Zhang et al. (2018) 로부터 크라우드소싱된 1155개의 페르소나를 사용한다
- Session 1
- 두 명의 화자가 처음으로 서로를 알아가는 짧은 대화들이 포함된 PersonaChat 데이터셋을 사용한다
- 화자들이 어떤 주제에 대해 깊게 토론하는 충분한 턴 수를 갖지 않기 때문에 대화가 피상적인 단계를 넘어서기는 어렵다는 점에 주목한다
- Session 2, 3, 4, ...
- 이전 session 이후 경과된 시간을 1~7 시간 또는 1~7일로 선택한다
- 크라우드 워커에게 이전 session과 동일한 역할을 수행하되, 해당 시간이 경과된 것처럼 행동하도록 한다
- 이렇게 하는 이유는 일을 단기로 하고 장기간에 걸쳐 쌍을 매칭하는 것이 불가능한 크라우드워킹 프레임워크에서 작업을 다루기 쉽게 하기 위함
- 크라우드 워커들이 부여받은 역할을 수행하는 것 뿐 아니라 다른 화자와의 이전의 상호작용에도 주의를 기울이도록 강조한다
- Session 길이
- 학습 데이터
- 3개의 session으로 이루어진 4000 episodes와 4개의 session으로 이루어진 1001 episodes
- 검증 및 테스트 데이터
- 최대 5개의 session으로 확장됨
- 학습 데이터셋의 분포를 넘어 확장된 긴 컨텍스트 session의 성능을 측정하는 방법을 제공
- 학습 데이터
- 대화 요약 (확장된 페르소나)
- 크라우드 워커에게 두 대화 역할 사이의 모든 이전 대화에 대한 접근 권한을 준다
- 대화가 길어질 수록 주어진 시간 내에 읽고 이해하기 어려우므로, 대화 요약을 한다
- 대화 요약은 각 세션이 끝날 때마다 크라우드 워커가 수행
- 이후의 session 대화를 위해 중요한 참조로 이 대화 요약을 보여준다
- 화자와 관련된 중요한 포인트가 요약되어 저장되므로, 이는 원래 주어진 페르소나의 확장이라고 볼 수도 있다
- Table 3
- 컨텍스트를 주지 않는 것 < 대화 컨텍스트 전체를 주는 것 < 요약 컨텍스트를 주는 것 순으로 좋은 성능
- Table 4
- 크라우드 워커가 요약한 Gold summary 기준으로, 자신에 대한 요약만 주거나 상대에 대한 요약만 주는 것보다 둘 다에 대한 summary를 모두 주는 것이 좋은 성능
- Table 5
- no_summary로 레이블링된 비율이 42%나 되므로, no_summary 레이블을 샘플링하는 비율에 따른 실험
- 샘플링 비율이 작을수록 좋은 성능
- Table 6
- Session 수를 늘려서 학습 데이터로 사용할 수록 좋은 성능
- 우리의 데이터셋은 (이전에는 쉽지 않았던) 긴 컨텍스트의 대화 모델을 훈련 및 평가하는 데에 사용될 수 있다
4 Modeling Mutli-Session Chat
4.1 Transformers 인코더-디코더
- 우리의 새로운 태스크를 이용해 대화를 모델링하는 가장 직접적인 접근법은 큰 언어 모델을 사용하는 것이다
- 우리는 초기 사전학습 모델로 BlenderBot의 BST 2.7B 파라미터 모델을 사용하며, MSC 태스크에 파인튜닝한다
- BST 2.7B 모델은 인코더의 truncation 길이가 128 토큰이므로 이를 늘리기 위해, 학습 가능한 positional encoding들을 256, 512, 1024 토큰으로 확장했다
- 다운스트림 태스크에 전체 네트워크를 파인튜닝하는 동시에 이 추가적인 파라미터들을 학습했다
- 다운스트림 태스크: 풀고자 하는, 적용하려는 태스크를 의미
- 기존 128 토큰의 임베딩이 변경되지 않도록 하면서 학습될 새로운 positional embeddings를 추가했다
4.2 Retrieval-Augmentation
- 많은 context가 있고 그 중 일부만 관련이 있을 때, Transformer 인코더를 사용하기 위한 인기 있는 기법은 Retrieval Augmentation을 사용하는 것이다
- retrieval 시스템은 디코더가 수반할 최종 인코딩에 포함될 부분을 context에서 찾아 선택하는 데에 사용된다
- RAG
- 검색할 문서 또는 passage는 approximate nearest-neighbor FAISS index에 저장되어 있고, DPR 모델을 이용해 이로부터 검색해온다
- 또한 DPR 모델을 이용해 관련도 상위 N개의 후보에 점수를 매긴다
- 전체 시스템은 end-to-end로 학습되어, 검색은 생성의 개선을 돕도록 최적화된다
- FiD and FiD-RAG
- retriever를 이용해 관련도 상위 N개의 문서를 반환 -> 문서들 각각을 context 앞에 이어붙임 -> 인코더로 각각 인코딩 -> 모든 인코딩 값들을 하나로 이어붙임 -> 디코더는 이 인코딩들을 주의하여(attend to) 최종 응답을 생성
- 사전학습된 retriever는 DPR 또는 FiD-RAG (RAG로 학습된 retriever)를 사용
- Retriever and Documents
- 메모리에 있는 passage 셋은 FAISS index가 필요할만큼 크진 않지만 검색이 유용할 정도로는 크다
- DPR 모델에 의해 메모리에 있는 모든 아이템에 대해 벡터 인코딩을 저장한다
- 대화 컨텍스트가 주어지면, 바이-인코더를 사용해 각 메모리(아이템)에 점수를 매기고, 상위 N개를 생성에 사용한다
- 메모리는 대화 발화들로 구성된다
- 발화들을 별도의 문서로 인코딩 또는 전체 세션(혹은 세션 요약)을 문서로 인코딩한다 => 후자가 좋은 성능
4.3 요약 메모리 Augmentation
- 히스토리가 있는 컨텍스트를 메모리에 그대로 저장하는 것은 간단한 방법이지만 두 가지 문제가 있다
- 저장할 컨텍스트가 많아서 검색할 컨텍스트도 많음
- 내용에 어떤 처리가 이루어지지 않기 때문에, 생성을 하기 위해 읽기, 검색, 결합 등 모델이 해야할 일이 많아짐
- 그래서 관련된 지식을 먼저 요약하고 그것을 저장하는 메모리 augmentation을 제안한다 (두 가지 구성 요소)
- 인코더-디코더 추상 요약기
- 대화 마지막 턴에서, 대화 히스토리를 입력으로 받아 새로운 관련있는 정보를 요약해서 장기 메모리에 저장한다
- 새로 저장할 정보가 없다고 판단하는 경우도 있다
- 어떤 요약을 생성해야 할지 알기 위해 MSC 태스크에 사람이 주석을 단 데이터를 사용할 수 있다
- 요약을 만들기 위해 지도학습된 인코더-디코더 모델을 학습시킨다
- 메모리-augmented 생성기
- 대화 컨텍스트와 장기 메모리에 대한 접근을 갖고, 다음 응답을 생성한다
- 인코더-디코더 추상 요약기
5 Experiments
- 세션 대화 컨텍스트
- 이전 세션 대화 컨텍스트를 주지 않을 때 < 이전 세션 대화 컨텍스트를 줄 때 < 이전 세션 대화 요약 컨텍스트를 줄 때 순으로 대체로 perplexity가 낮아졌다
- 대화 요약 컨텍스트는 크라우드 워커가 주석을 달아둔 것을 사용
- 컨텍스트 truncation 길이를 크게 할수록 perplexity가 낮아졌다 (128 < 512 < 1024)
- 이전 세션 대화 컨텍스트를 주지 않을 때 < 이전 세션 대화 컨텍스트를 줄 때 < 이전 세션 대화 요약 컨텍스트를 줄 때 순으로 대체로 perplexity가 낮아졌다
- 세션 opening
- MSC 데이터셋에는 시간이 좀 지난 후에 다른 화자가 재참여하도록 하기 위한 opening 메시지가 있다
- opening 메시지는 화자끼리 이야기를 나눈 알려진 정보이다
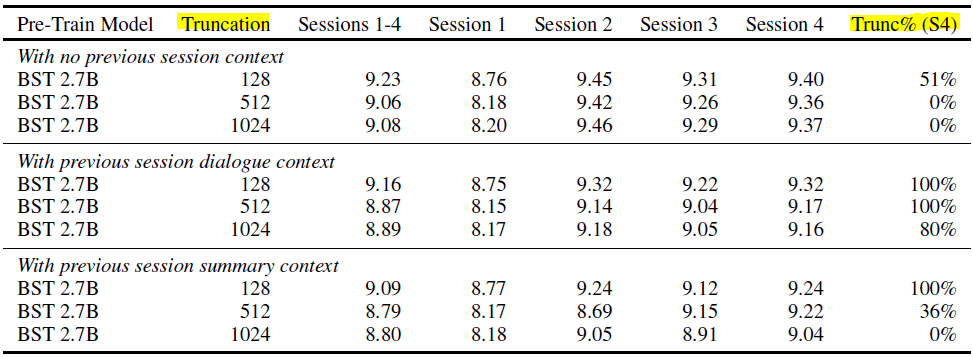
- 컨텍스트 길이
- Table 3의 Trunc% (S4) 열을 비교 (Session 4에서 토큰들이 truncation된 비율을 의미)
- truncation 길이 값이 작을수록 많이 손실됨
- 대화 컨텍스트를 사용하는 것보다 대화 요약 컨텍스트를 사용할 때, 컨텍스트 길이 자체가 짧기 때문에 손실되는 양이 적음 => 성능 향상에 도움이 될 수 있음
- 대화 요약 컨텍스트
- 시간 특성(이전 세션이 발생한지 얼마나 지났는가)을 제거하는 것은 효과가 없음
- 파트너 요약 또는 본인 요약을 제거하면 성능이 떨어지므로 둘 다 유지하는 것이 좋음
- 학습 세션 수
- 세션 수를 늘릴 수록 perplexity가 낮아지긴 하나 점점 그 차이가 작아짐
- 1개에서 2개로 늘리면 대폭 개선됨. But, 3개에서 4개로 늘리면 아주 미세하게 개선됨.
- 요약 예측 모델
- 학습 데이터는 각 턴마다 요약 문장 또는 no_summary 레이블로 이루어짐
- 이전 세션에서 예측된 대화 요약을 컨텍스트로 사용
- 샘플링 실험
- 전체 턴의 42%가 no_summary 레이블을 갖기 때문에, beam decoding 시에 overexpressed 될 수 있음
- 따라서 학습 시에 no_summary 레이블을 K%만 샘플링하도록 실험
- subsampling은 인간이 주석을 단 원래의 데이터에 더 좋은 결과와 더 가까운 희소성 수준을 가져다준다 (no_summary 레이블이 아닌 요약 문장들의 영향력을 높인다는 뜻인 듯)
- 컨텍스트로 K=5% 샘플링으로 예측한 요약을 사용했을 때, 대화 히스토리를 사용한 것보다는 성능이 좋았고 골드 대화 요약을 사용한 것보다는 좋지 않았다
- Retrieval-augmented 모델
- 사전학습된 BST 2.7B 모델을 MSC 데이터셋으로 학습. 검색 증강 방법으로는 RAG / FiD / FiD-RAG 를 비교
- 세 가지 검색 증강 방법 모두 대화 히스토리 길이를 확장하는 데에 검색을 효과적으로 사용
(이해가 안되었음) - 검색 증강 모델은 대화가 얼마나 길어지든 대화를 절대 잊지 않는 메모리가 있다 (truncation 모델은 그렇지 않다)
- 요약 메모리 모델
- 이전 대화 히스토리를 요약한 다음, 모델의 장기 메모리인 SumMem-MSC 2.7B에 저장한다
- 장기 메모리로부터 검색을 하기 위해 RAG / FiD / RAG-FiD를 사용하거나 (Retrieval-augmented 모델), 또는 대화 컨텍스트를 truncate한 1024개 토큰의 고정된 메모리와 비교한다 (truncation 모델)
- SumMem-MSC 2.7B 모델에서, RAG < FiD < FiD-RAG 순 성능
- FiD와 FiD-RAG > truncation 모델 성능
- SumMem-MSC 모델 > MSC 2.7B 모델 성능
- 최종적으로 SumMem-MSC 2.7 (FiD-RAG) 모델이 가장 좋은 성능
- 사람 평가
- 크라우드 워커를 통해 평가
- 평가 셋으로부터 랜덤하게 2개의 페르소나를 선택한 다음, 1개는 크라우드 워커에게, 1개는 봇에게 할당하여 대화를 시작함
- 두 화자가 대화할 session 5가 될 대화를 선택하고, 이전의 session 1~4의 요약을 제공한다
- 크라우드 워커는 자연스러운 대화를 나누면서 파트너의 응답을 평가한다
- 특히, 이전 세션들에서 나왔던 본인 또는 다른 화자의 페르소나(또는 토론을 했던 주제)에 대한 지식을 참조했는지에 대해 평가
- 대화의 각 턴마다, 마지막 턴에 해당하는 특성 박스를 모두 체크해야 한다
- 각 대화는 15개의 메시지로 구성된다 (7개는 사람, 8개는 봇으로부터)
- 대화가 끝날 때, 파트너의 전반적인 매력도 점수를 매긴다
- 결과
- MSC 2.7B 모델이 BlenderBot (BST 2.7B) 모델보다 대체로 좋다
- 요약 메모리 모델(= SumMem-MSC)이 MSC 2.7B (truncation) 모델보다 대체로 좋다
- 요약 메모리 모델에서, 이전 세션들에 나온 파트너의 주제를 참고하는 비율이 크게 증가했다 => 매력도에서 높은 점수를 얻을 수 있었던 이유로 봄

6 Conclusion
- 대화에 대한 기존의 접근법들은 학습 데이터와 학습 모델 측면 모두에서 장기적인 대화를 적절히 하지 못한다
- 우리는 이를 해결하기 위해 다양한 모델 아키텍처를 조사하고, 모델들을 학습 및 평가하기 위해 Multi-Session Chat이라는 새로운 크라우드소싱 태스크를 수집했다
- 우리의 장기적인 컨텍스트 대화 모델링 접근법은 자동 평가지표와 사람 평가 측면 모두에서 이전의 접근법들을 능가한다
- 따라서 우리의 연구는 대화 연구에서 누락된 심각한 부분을 해결하는데 기여하며, 이 분야에서의 발전을 평가하는 수단을 제공한다
- 추후에는 장기적인 컨텍스트 대화 세팅을 위한 아키텍처를 더 발전시킬 것이다
7 Societal Impact
- 우리가 이 연구에서 사용한 대화 모델은 큰 언어 모델을 활용하는데, 여기에는 특히 toxic 언어, bias, 그리고 언어 생성 시에 발생하는 다른 이슈들과 같은 우려가 있다
- 우리의 연구는 장기 기억과 오픈 도메인 대화를 하는 모델에 초점을 둔다
- 크라우드 워커들은 자기 자신에 대해 얘기하지 않고 주어진 페르소나에 따라 역할을 수행했으므로, 개인 정보를 식별하지 않는다
- 모델은 대화 시에 배운 정보를 모델의 메모리에 장기적으로 저장하며, 이 정보는 개개인의 대화에서만 사용되며 다른 사람과 공유되지 않는다
나의 요약
- 컨텍스트 안 주는 것 < 대화 컨텍스트 주는 것 < 대화 요약 컨텍스트 주는 것
- 이전 세션에서의 컨텍스트를 안 주는 것보다 주는 것이 좋고, 주는 것 중에는 대화 히스토리를 다 (최대 길이만큼) 주는 것보다 대화 요약을 주는 것이 좋다
- truncation 모델보다 Retreival-augmented 모델이 더 좋다
- truncation 모델: 컨텍스트 길이를 고정된 값으로 truncation하는 방법
- Retreival-augmented 모델: 모델의 장기 메모리에 저장된 컨텍스트에서 관련 있는 부분을 검색해오는 방법
- 검색 증강 방법은 RAG < FiD < FiD-RAG
- 모델은 BST < MSC < SumMem-MSC
- SumMem-MSC 는 장기 메모리를 갖는 모델
- 대화 마지막 턴에서, 대화 히스토리를 입력으로 받아 새로운 관련 정보를 요약해서 장기 메모리에 저장한다
- 다음 대화 시에 장기 메모리로부터 Retreival-augmented 모델로 관련 컨텍스트를 검색해와서 응답을 생성한다
반응형