Transformer 이해하기

[Encoder]
- Multi-Head Attention
우선 이건 Self-Attention이다.

이 그림을 이해해보자.

Q : 영향을 받을 단어
K : 영향을 주는 단어
V : 영향에 대한 가중치
참고한 블로그의 표현을 빌려, 위와 같이 Q, K, V의 역할을 이해하면 된다.
Self-Attention이기 때문에 Query, Key, Value는 입력 문장의 단어 벡터에 해당한다.
Multi-Head Attention은 Attention은 병렬로 여러 개 수행하는 것이다. (한번의 Attention을 하는 것보다 여러 번의 Attention을 병렬로 수행하는 것이 성능이 더 좋기 때문이라고 한다)
Attention Head 수가 h라고 할 때, W^Q, W^K, W^V를 랜덤하게 h쌍 만든다. 그리고 각각의 W^Q, W^K, W^V를 입력 벡터 X와 dot product 연산하여 h쌍의 Q, K, V를 만든다.
여기까지가 아래 그림에 해당한다.


이제 이 Q, K, V 벡터에 대해 Scaled Dot-Product Attention을 수행한다.


$d_k = embed\_dim // num\_heads$
$d_k$는 scaling factor로, 각 head에 배분된 임베딩 벡터의 크기를 의미하고 head_dim이라고도 한다.
scaling을 하는 이유는 다음과 같다.
$Q*K^T$의 연산 값이 매우 크다고 가정하고 이 값을 M이라고 해보자. 값 M에 softmax를 씌워야 하는데, softmax의 수식을 보면 모든 값들에 대해 지수함수를 씌운 $e^x$를 모두 더한 것이 분모가 된다. 즉 여기에는 $e^M$도 포함된다. 그런데 M은 이미 매우 큰 값인데 여기에 지수함수를 씌우면 그 값이 매우매우 커지게 된다. 그래서 어떤 입력이 들어오더라도 softmax의 분모가 매우 크기 때문에 항상 softmax 출력 값이 0에 가까워진다. 이는 모델이 학습 시에 gradient를 제대로 전파하지 못하는 결과를 낳는다.

따라서, 내적 연산 값이 매우 커지는 걸 방지하기 위해서 scaling하는 과정이 필요한 것이다.
이 연산을 h쌍의 Q, K, V 벡터에 대해 수행하여 h개의 Z를 얻게 되는데, Z를 Attention head라고 한다. 이 연산은 아래 부분에 해당한다.


이제 h개의 Attention head들을 Concat하고, W_O와 Linear 연산하여 Multi-Head Attention의 최종 결과인 Z를 얻어낸다.


Multi-Head Attention 전체를 수식으로 나타내면 다음과 같다.

Multi-Head Attention과 내부의 Scaled Dot-Product Attention까지 이해 완료~!
- Position-wise Feed-Forward Networks
그냥 Fully-connected Feed-Forward Network인데, 'Position-wise'의 의미는 각 단어마다 Feed-Forward Network를 적용한다는 것이다! (겁낼 필요 없다)
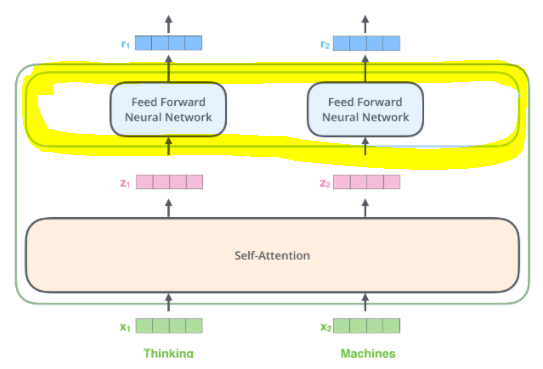

Linear 연산을 수행하고 그 결과에 ReLU를 씌운 다음 Linear 연산을 한번 더 수행한다.
(Linear 연산은 filter size가 1인 Conv1d로 구현할 수도 있다.)
[Decoder]

Masked Multi-Head Attention
: Self-Attention이다. Query, Key, Value는 모두 입력 문장의 단어 벡터.
Multi-Head Attention
: Encoder-Decoder Attention이다. Query는 현재 Decoder 레이어에서 Masked Multi-Head Attention과 Add & Norm을 거친 출력이고, Key와 Value는 Encoder의 최종 출력.
- Masked Multi-Head Attention
Self-Attention이다. Query, Key, Value는 모두 입력 문장의 단어 벡터이다. (=> 입력 문장 내 단어들 간의 연관성을 파악)
RNN 기반 Decoder에서는 매 time step마다 순차적으로 단어를 입력받지만, Transformer의 Decoder에서는 입력 문장을 통째로 받는다. 이에 따라 입력 문장으로부터 현재 시점보다 미래 시점의 단어도 참고할 수가 있다는 문제가 발생한다. 그래서 미래 시점의 단어를 참고하지 못하도록 Mask를 사용한다.

Mask의 역할은 쉽게 말해, i번째 입력 토큰에 대한 연산을 해야할 때 (i+1)번째부터의 입력 토큰들은 연산 과정에서 보지 못하도록 가리는(masking) 것이다. 이로써 0~i번째의 입력 토큰들만 보고 연산을 수행할 수 있게 된다.
Masked Multi-Head Attention 연산 과정을 자세히 살펴보자.
우선 attention mask에서 masking하지 않을 0~i번째 인덱스 값에는 0을 할당하고, masking할 (i+1)번째부터의 인덱스 값에는 -∞를 할당한다. Query와 Key 간의 dot product를 계산해 attention weight를 얻고, 여기에다가 attention mask를 더해준다. 그리고 softmax를 수행하면, 0~i번째 인덱스에서는 올바르게 확률 값이 계산되고, (i+1)번째 인덱스부터는 softmax(-∞) = 0 이므로 모두 0 값을 갖게 된다. 마지막으로 Value와의 dot product 연산을 수행함으로써 최종적으로 attention value를 얻을 수 있다.
- Multi-Head Attention
Encoder-Decoder Attention이다. Query는 현재 Decoder 레이어에서 Masked Multi-Head Attention과 Add & Norm을 거친 출력이고, Key와 Value는 Encoder의 최종 출력이다. (=> Encoder 값과 Decoder 값 간의 연관성을 파악)

참고한 블로그
- https://blog.naver.com/winddori2002/222008003445
- http://jalammar.github.io/illustrated-transformer/
- https://velog.io/@crosstar1228/NLPTransformer-Attention-is-all-you-need-%EC%83%85%EC%83%85%EC%9D%B4-%ED%8C%8C%ED%97%A4%EC%B9%98%EA%B8%B0#causality-masking
참고하면 좋을 영상