
[StarGAN] 코드 파악하기 - solver.py (2)
-> 이전 글
[StarGAN] 코드 파악하기 - solver.py (1)
초보자라 틀린 부분이 있을 수 있습니다. 피드백 주시면 감사히 반영하겠습니다 :) solver.py는 코드가 길어서 글을 두 개로 나눠서 적을 것이다. Solver 클래스는 nn.Module을 상속받지 않는다. Solver 객
beausty23.tistory.com
이번 포스팅에서는 solver.py의 182번째 줄부터 파악해본다.
초보자의 입장에서 구조 파악이 어려운 부분이 꽤 있으니 해당 코드를 직접 실습해보면서 구조를 직접 확인해보는 것을 추천한다.

단일 데이터셋을 사용할 때 학습을 진행하는 train() 함수이다. (여러 데이터셋을 사용할 때의 train_multi() 함수는 다루지 않을 것이다)
dataset 값에 따라 data_loader에 해당하는 data loader를 할당한다.
iter() 함수는 data_loader에 대한 이터레이터를 반환해 data_iter에 할당하고, next() 함수를 통해 data_loader에 대한 이터레이터에서 값을 하나 꺼내 각각 x_fixed와 c_org에 저장한다. (next() 함수를 호출할 때마다 이터레이터 내의 값이 순차적으로 꺼내진다)
x_fixed에는 batch_size개의 이미지가 담긴 tensor가, c_org에는 각 이미지의 도메인 레이블이 담겨 있는 tensor가 저장된다.
이전 글에서 설명한 create_labels() 함수를 통해, batch_size개의 이미지에 대해 모든 가능한 타겟 도메인들을 생성하여 c_fixed_list에 할당한다.
main.py의 인자에서 'resume_iters'는 default가 None이지만 resume_iters 값을 설정해줌으로써 이전까지 수행했던 iteration에 이어서 학습을 시작할 수 있다.
resume_iters 값을 start_iters 값에 할당해 해당 iteration부터 시작한다. restore_model() 함수를 통해 resume_iters에 해당하는 저장된 모델을 복원한다.
여기까지 문제 없이 잘 진행되었다면 'Start training...' 이라는 문구가 출력된다.
학습 시작 시간을 start_time에 저장한다.
i는 start_iters부터 num_iters-1까지의 값을 가지며 line 209 ~ 339을 반복한다.
먼저 전처리 단계이다.
data_loader에 대한 이터레이터로부터 값을 하나 꺼내서 각각 x_real과 label_org에 저장한다. x_real에는 한 batch에 대한 텐서, label_org에는 한 batch 내 각 이미지의 도메인 레이블을 담은 텐서가 저장된다.
label_org.size(0)은 batch_size를 의미한다. 이를 randperm() 함수의 인자로 넣으면 0 ~ batch_size-1의 값을 무작위의 순서로 갖는 중복되지 않는 순열(배열)을 반환한다.
label_trg = label_org[rand_idx]는 rand_idx의 각 값을 label_org의 인덱스로 함으로써 무작위로 생성된 타겟 도메인들을 label_trg에 할당한다.
(label_trg[0]=c_org[10]=3, label_trg[1]=c_org[15]=2, ...)
label2onehot() 함수에 label_org 또는 label_trg를 넘겨주면 각 도메인 레이블 값에 대한 one-hot vector가 만들어진다.
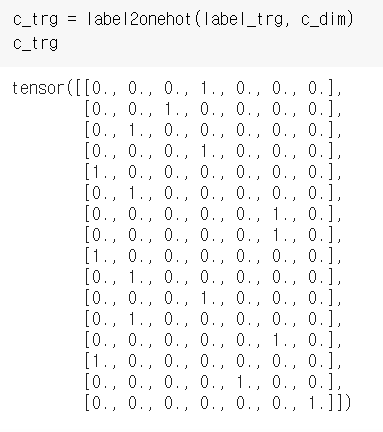
(label_org[0]=3이 label2onehot() 함수를 통해 [0., 0., 0., 1., 0., 0., 0.]으로 변환된 것을 볼 수 있다)

다음은 Discriminator 학습 단계이다.
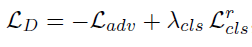
논문에 따르면 Discriminator의 Loss 식은 위와 같고, L_adv와 L_cls_r 식을 세부적으로 살펴 보면 다음과 같다.
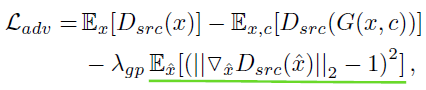
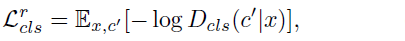
L_adv는 원본 이미지에 대한 Real/Fake 판별 값의 평균 - 합성 이미지에 대한 Real/Fake 판별 값의 평균 - 상수 * gradient penalty 로 구한다.
L_D 식을 보면 L_adv 식에 (-)를 붙인다. 따라서 이 음의 부호를 식에 분배하여 - E_x[D_src(x)] + E_x,c[D_src(G(x,c))] + λ_gpE_x^[식 생략 ] 를 구하도록 한다.
L_cls_r은 원본 이미지에 대한 domain classifiaction loss를 cross entropy로 구한다.
각 loss 식의 형태를 알아두고 이제 코드를 살펴 보자.

먼저 원본 이미지에 대한 loss를 계산한다.
1줄에서 원본 이미지를 Discriminator의 입력으로 넣어 출력 값을 각각 out_src, out_cls에 저장한다.
2줄에서 out_src의 값에 대해 평균을 낸 다음(=>E_x[D_src(x)]) 음의 부호를 붙여 d_loss_real에 저장한다. 위에서 설명한 바에 따라서 음의 부호를 붙이는 것에 유의한다.
3줄에서는 Discriminator로 예측한 domain classification 값(out_cls)과 실제 도메인(label_org) 사이의 loss를 classification_loss() 함수로 구해 d_loss_cls에 저장한다.
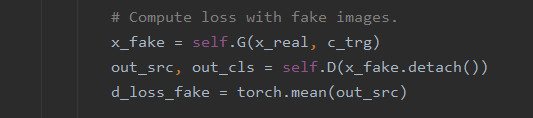
합성된 이미지에 대한 loss를 계산한다.
1째 줄에서 batch_size개의 원본 이미지들을 랜덤으로 생성된 타겟 도메인으로 합성하여 x_fake에 저장한다.
이 합성된 이미지에 대해 Discriminator로 예측한 Real/Fake 판별 값의 평균을 구해 d_loss_fake에 저장한다.

alpha는 x_real.size(0) (=batch_size) 갯수의 [0,1) 범위의 랜덤한 값을 저장한다.
x_hat을 구하는 식은 넘어가고, 이 x_hat을 Discriminator에 집어 넣어 out_src를 얻는다. gradient_penalty() 함수를 통해 얻은 값이 d_loss_gp이다. 이는 L_adv 식에서 초록색 밑줄에 해당한다.

이제 L_D를 구한다.
d_loss_real은 -E_x[D_src(x)], d_loss_fake는 E_x,c[D_src(G(x,c))], lambda_cls는 λ_cls, d_loss_cls는 L_cls_r, lambda_gp는 λ_gp에 해당, d_loss_gp는 초록색 밑줄 부분에 해당한다.
optimizer의 gradient를 초기화시킨다.
그리고 d_loss에 대해 역전파를 진행한다. 이 때 backward() 함수는 torch.autograd.Variable 클래스에 정의된 것으로 자동으로 미분 값 계산을 해준다. 이곳에 설명이 매우 잘 되어 있으니 참고하면 좋을 것 같다.
optimizer에 대해 step()을 해주면 매개변수가 갱신된다.

다음은 Generator 학습 단계이다.


n_critic은 Discriminator가 몇 번 업데이트 됐을 때마다 Generator를 1번 업데이트할 것인지를 나타내는 값이었다.
Discriminator 학습 횟수를 나타내는 i+1에 대해 n_critic번의 주기마다 Generator의 학습을 진행한다.
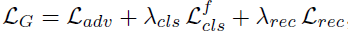
Generator의 Loss를 나타내는 L_G의 식은 위와 같고, L_adv, L_cls_f, L_rec의 식을 자세히 살펴보면 아래와 같다.
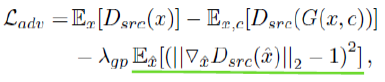
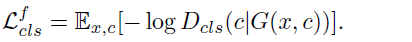
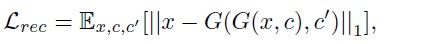
L_adv는 Discriminator에서도 사용되었으므로 넘어가고, L_cls_f는 Generator에서 생성된 가짜이미지에 대한 domain classification loss이다. L_rec는 Generator에서 생성된 합성 이미지를 또 Generator의 입력으로 넣고 타겟 도메인을 원본 도메인으로 하여 생성된 원본에 가까운, 즉 reconstruction된 이미지와 실제 원본 이미지 사이의 loss인 reconstruction loss를 의미한다.
이제 코드를 살펴보자.

이 부분은 Discriminator에서와 동일하므로 넘어간다.

Generator를 한 번 거쳐 생성된 가짜 이미지(x_fake)와 원본 이미지의 도메인(c_org)를 Generator의 입력으로 하여 생성된 이미지를 x_reconst에 저장한다. reconstruction loss는 |원본 이미지 - reconstruct 이미지|의 평균을 구함으로써 얻는다. 이를 g_loss_rec에 저장한다.

1줄이 L_G를 구하는 식인데, g_loss_fake는 L_adv 식의 -E_x,c[D_src(G(x,c))]에 해당하고, lambda_rec는 λ_rec, g_loss_rec는 L_rec, lambda_cls는 λ_cls, g_loss_cls는 L_cls_f에 해당한다.
잘 보면 식이 맞지 않는다. L_adv 식에서 loss_real에 해당하는 E_x[D_src(x)]와 gradeint penalty 항이 빠져 있다. 이 이유에 대해서는 github.com/yunjey/stargan/issues/26에 개발자가 답변을 주었다. loss_real 항이 빠져 있는 이유는 Generator에서는 loss_real 값을 계산하지 않기 때문이라고 한다. Generator는 가짜 이미지를 생성하는 역할을 하므로, 생성된 가짜 이미지에 대한 loss를 계산하는 과정만 필요하지 원본 이미지에 대한 loss는 계산할 필요가 없기 때문이다.
하지만 gradient penalty 항은 왜 생략되는 것인지는 이해하지 못하였다.
하여튼 g_loss에 대해서도 backward 계산을 진행해준다.

Miscellaneous에서는 학습 정보 출력, 샘플 이미지 저장, 학습 모델 저장, learning rate 감소를 수행한다.
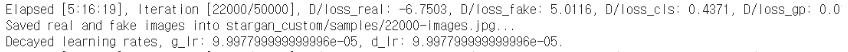
학습 시 위와 같이 출력되고 저장된다.
하나의 데이터셋만을 사용할 것이므로 train_multi(), test_multi() 함수는 건너뛴다.

이제 test() 함수를 살펴 본다.

몇 번째 학습 모델을 가지고 테스트를 진행할 것인지를 의미하는 test_iters를 이용해 해당하는 모델을 restore_model로 가져온다.
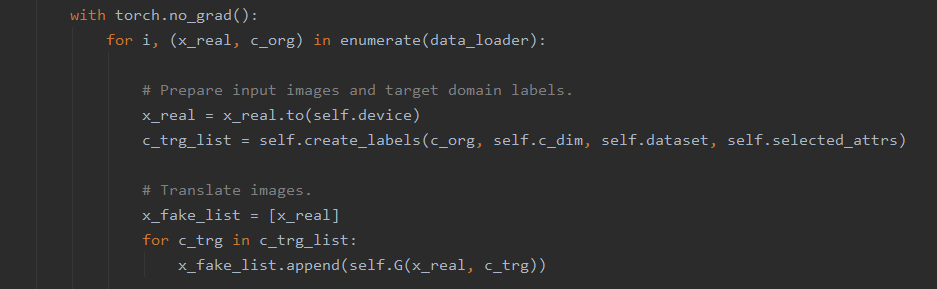
위에서 backward() 함수 참고 링크에서 보았듯이 gradient 계산 시 연관된 텐서를 역으로 추적한다. 이 때, 특정 코드 블럭에서 gradient 계산을 위한 기록 추적이 일어나지 않게 하기 위해 with torch.no_grad()를 사용한다. (여기를 참고하면 좋을 듯)
for문이 반복될 때마다 data_loader로부터 한 batch를 가져와 batch_size개의 이미지와 각 도메인을 x_real, c_org에 저장한다.
batch_size개의 이미지에 대해 가능한 모든 타겟 도메인을 저장한 c_trg_list는 아래와 같은 구조를 갖는다.

x_fake_list에 먼저 원본 이미지들을 저장해둔다.
그리고 c_trg_list의 각 batch에 대해 원본 이미지를 Generator를 이용해 합성하고 결과물을 x_fake_list에 집어넣는다.

'result_dir' 인자에 지정해준 경로에 '1-images.jpg'와 같은 이름으로 결과물이 저장된다.
모든 테스트 이미지에 대해 모든 타겟 도메인으로 합성을 진행한 결과물이다.
solver.py 파악 완료!
참고
iter(), next() : dojang.io/mod/page/view.php?id=2408
shape 확인 : data-panic.tistory.com/10
randperm() : pytorch.org/docs/stable/generated/torch.randperm.html
cross_entropy() : blog.naver.com/PostView.nhn?blogId=gyrbsdl18&logNo=221013188633
rand() : pytorch.org/docs/stable/generated/torch.rand.html
backward() : taewan.kim/trans/pytorch/tutorial/blits/02_autograd/
step() : tutorials.pytorch.kr/beginner/examples_nn/two_layer_net_optim.html